СОДЕРЖАНИЕ
1. Глобальная архитектура системы
1.2.2 Диаграмма классов пакета Meta
1.2.3 Диаграмма классов пакета reader
1.2.5 Диаграмма классов пакета model
1.2.6 Диаграмма классов пакета handler
1.2.7 Диаграмма классов пакета painter
1.2.8 Диаграмма классов пакета outer
1.2.9 Диаграмма классов pipeline
1.4 Оптимизация скорости работы алгоритмов
1.5 Тестирование качества, скорости, отказоустойчивости системы
1.6 Поиск ошибок и некорректной работы
2. Поиск, сбор, анализ, разметка и обогащение данных
2.1 Создание требований по данным для обучения алгоритмов
2.2 Используемые наборы данных
2.3. Поиск и выбор оптимальных параметров камер
2.4 Формирование заданий на сбор и разметку данных
3. Выбор подходов и алгоритмов
4. Алгоритмы определения положения объектов в пространстве и расстояния между ними
4.1. Тестирование, оптимизация алгоритмов
5.1 Дефекты на твердом материале
6.3 Распознавание номера вагона поезда
6.4 Распознавание QR и штрихкодов
7.2. Тестирование, оптимизация скорости работы алгоритмов
9. Разработка компонента системы для определения положения объектов в пространстве
10. Разработка моделей определения скорости объектов
11. Внедрение в алгоритмы компьютерного зрения инструментов и методов проективной геометрии.
12.2. Архитектура сети для предсказания размера набора данных
12.3. Подготовка набора данных для обучения модели
12.4. Предсказание размера набора данных
13. Разработка графического интерфейса пользователя
13.1. Интерфейс калибрации для стереозрения
13.2. Интерфейс для ручного выбора объектов для отслеживания
13.3. Интерфейс для оценки размера тренировочного набора изображений
14. Разработка методов автоматического машинного обучения, релевантных для поставленных задач
15. Оценка разработанной библиотеки и формирование документации .
15.2 Тестирование, оптимизация скорости работы алгоритмов
16. Применений алгоритмов к уже реализованным проектам и оценка качества.
16.1 Применение алгоритмов расчёта положения объектов в пространстве
16.2 Применение алгоритмов гранулометрии
17. Сравнение реализованной библиотеки с аналогами.
Список использованных источников
Введение
С каждым днем увеличивается потребность автоматизации контроля производственного процесса и качества производимых товаров, актуальной становится задача автоматического управления производственным процессом. В настоящее время существует достаточно большое количество открытых решений для конкретных, индивидуальных подзадач, но они не объединены в единую универсальную систему. Такие системы являются коммерческими, засекреченными и дорогими, что не позволяет осуществить их массовое внедрение. Настоящая документация детально описывает создание универсальной системы контроля производственного процесса на основе алгоритмов компьютерного зрения и глубокого обучения для анализа видеопотока. Рассмотрены задачи распознавания дефектов, классификации объектов, положение объекта в пространстве, производится анализ перемещения объектов (тректинг), качественное решение которых позволит управлять производственным процессом в реальном времени. Разработанная система снабжена графическим интерфейсом, который открывает ее более широкому кругу пользователей. Обучающая выборка состоит из огромного количества видео материалов, собранных компание за годы работы с крупнейшими промышленными предприятиями России. Качество созданного решения подтвержается его применения на реальных производствах, в частности таких компаний, как Евраз, Русал, Норильский Никель и многих других.
Библиотека состоит из большого количества предобученных моделей, задача которых – автоматическое управление производственным процессом по видеопотоку, в том числе: автоматическая оценка качества выпускаемой и принимаемой продукции и результатов технологических операций, промышленная безопасность, автоматическое принятие решений в ходе процесса и автоматическое отслеживание объектов.
Ход реализации:
● Разработка архитектуры библиотеки (рассматривается в главе 1).
● Поиск, сбор, разметка и обогащение данных (описана в главе 2).
● Определение положения объекта (детали производственного оборудования, человека, машины) в пространстве и расстояния между ними (глава 3).
● Распознавание дефектов и прочих образований на материале (глава 4) .
● Распознавание номера объекта (автомобиля, вагона поезда, других объектов на производстве или в городской среде) (рассмотрено в главе 5).
● Анализ перемещения объектов (людей, машин и других) в пределах установленной области (описан в главе 6).
● Определение размеров объекта (для автомобилей и прочих т/с и для руды на конвейере) (глава 7).
● Возможность системы обучиться решать одну из указанных выше задач для новой категории объектов при условии предоставления обучающих данных – данная задача рассматривается во всех главах, так как алгоритмы проектировались с учетов возможности дообучения.
ОСНОВНАЯ ЧАСТЬ
1. Глобальная архитектура системы
Основная причина разработки данного фреймворка – предоставить полный инструментарий для построения конвейеров самых часто используемых задач компьютерного зрения, а также следует предусмотреть возможность расширения для реализации дополнительных возможностей. Универсальность всей планируемой системы не позволяет использовать один алгоритм, поэтому для каждой конкретной задачи потребуется выбор оптимальной архитектуры нейронной сети. Поставленные задачи планируется решать с помощью детекции объектов, их локализации, сегментации, трекинга и предсказания траектории движения, распознавания символов и классификации объектов. Результатом работы должен быть фреймворк, позволяющий
строить готовые конвейеры для различных задач компьютерного зрения, а также изменять функционал уже готовых конвейеров путём передачи в него разных моделей нейронных сетей. В разделе описана разработанная блочная система, которая позволит строить гибкие конвейеры, в которых можно изменять архитектуры нейронных сетей.
1.1 Требования к системе
1.1.1 Функциональные требования
1. Библиотека должна поддерживать входные видеопотоки с веб камер, из файлов, с IP камер.
2. Библиотека должна быть способна работать с моделями классификации, детекции и сегментации.
3. Библиотека должна быть способна рисовать ограничивающие рамки для задач детекции, маски для задач сегментации и писать метки для задач классификации, в том числе текстовые.
4. Библиотека должна поддерживать несколько источников ввода.
5. Библиотека должна быть способна работать с различными архитектурами нейронных сетей.
6. Библиотека должна иметь модуль трекинга для подключения к моделям детекции.
7. Библиотека должна уметь работать как с CPU , так и с GPU.
8. Библиотека должна уметь подсчитывать количество объектов для задач детекции.
9. Библиотека должна позволять сохранять веса моделей машинного обучения и их архитектуру.
1.1.2 Нефункциональные требования
1. Библиотека должна быть реализована на Python.
2. Библиотека должна быть реализована с помощью PyTorch.
3. Возможность расширения новым функционалом для задач компьютерного зрения.
4. Скорость работы конвейера должна не уступать аналогам.
1.2 Архитектура
В идею заложено создание структур данных, которые будут называться метаданные, содержащие изображения и информацию о них. Эта информация, как и сами изображения внутри могут меняться в зависимости от компонента, в который они переданы. Компонентами будут служить классы, которые наследуются от абстрактного класса, имеющего метод do , который необходимо реализовать всем компонентам. Каждый из этих компонентов будет обрабатывать данные по-своему и возвращать тот же объект, что был ему передан, но с измененными полями. Таким образом, достигается масштабируемость и гибкость функционала фреймворка.
1.2.1. Диаграмма пакетов
Каждый пакет в пакете components на рисунке 2.1 является следствием решения одного из функционального требования.
Рисунок
1.1 - Диаграмма пакетов системы
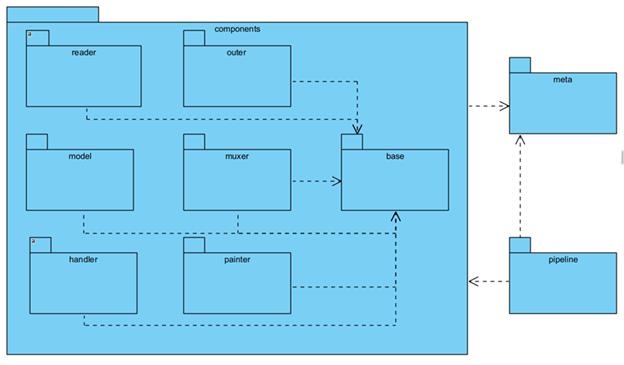
● reader – пакет с компонентами, выполняющими функцию чтения изображений и видеопотоков;
● muxer – пакет, содержащий компонент для объединения потоков данных из различного количества источников, считанными компонентами пакета reader;
● model – пакет, содержащий компоненты для работы с моделями фреймворка PyTorch.
● painter – пакет, содержащий компоненты для отрисовки ограничивающих рамок, масок и классов. А также содержит компонент для объединения нескольких потоков данных в один в виде сетки.
● handler – пакет содержащий компоненты, для фильтрации предсказаний, а также подсчёта объектов.
● base – пакет, содержащий класс, от которого наследуются все компоненты, перечисленные выше. Он реализует необходимые методы для работы со всем компонентами фреймворка.
● meta – пакет, содержащий структуры данных, которыми оперируют компоненты фреймворка.
● pipeline – пакет, содержащий конвейер, класс, который передает структуры данных meta между компонентами. Также собирает и закрывает компоненты.
1.2.2 Диаграмма классов пакета Meta
На рисунке 1.2 изображены классы, которые являются хранилищем для данных, полученных из компонентов. Это структуры данных, которые являются переносчиками информации между компонентами, как для работы с ними, так и для работы с конвейером.
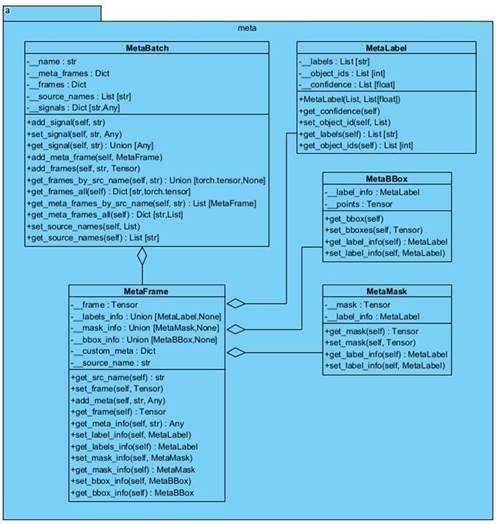 |
Рисунок 1.2 – Диаграмма классов пакета meta
● MetaLabel – класс, хранящий информацию о классах, изображений, масок и ограничивающих рамок;
● MetaBBox – класс, хранящий информацию об ограничивающих рамках и их классах;
● MetaMask – класс, хранящий информацию о масках и классах.
● MetaFrame – класс, хранящий изображение, а также всю информацию, полученную от компонентов об этом изображении.
● MetaBatch – класс, хранящий все изображения из различных источников. Также ModelBatch хранит сигналы, получаемые из компонент, и служит в роли шины.
Для задач, не относящихся к классификации, сегментации или детекции в классе MetaFrame есть поле, которое предназначено для хранения данных, которые могут пригодиться при расширении функционала.
1.2.3 Диаграмма классов пакета reader
На рисунке 1.3 представлена подробная диаграмма классов пакета reader . Задача этих компонентов чтение данных из различных источников.
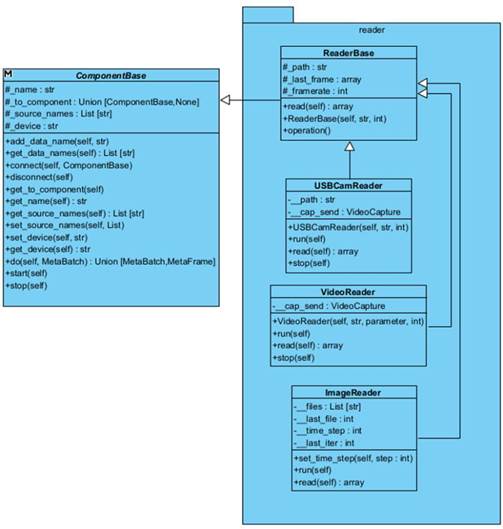 |
Рисунок 1.3 – Диаграмма классов пакета reader
1.2.4. Диаграмма классов пакета muxer
На рисунке 1.4 изображен пакет muxer . Задача этих компонентов объединение видеопотоков путём добавлений MetaFrame в MetaBatch , с которым работают все компоненты.
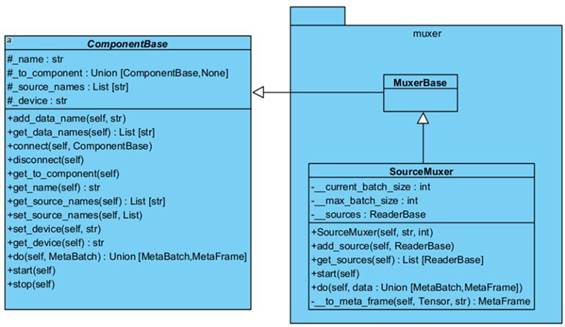 |
Рисунок 1.4 – Диаграмма классов пакета muxer .
● MuxerBase – абстрактный класс без полей и методов, необходим для того, чтобы пользователь имел возможность от наследоваться и реализовать свой класс Muxer . Класс MuxerBase служит логическим обособлением от класса ComponentBase.
● SourceMuxer – класс, объединяющий потоки данных из разных источников и формирующий из MetaFrame пакеты, передавая в MetaBatch.
Данный компонент позволяет получать видеопотоки из различных источников, получаемых компонентами-наследниками ReaderBase . Также оборачивает изображения в объекты типа MetaFrame , которые содержат само изображение, а также название источника, из которого оно было получено. Благодаря этому, каждый из компонентов сможет использовать видеопотоки, полученные из нужных источников, что позволит строить длинные конвейеры, которые на выводе будут давать разный результат в зависимости от источника ввода.
● ReaderBase – абстрактный класс содержащий метод read(self ), который необходимо реализовать всем классам наследникам. Этот метод считывает кадр из источника и возвращает его.
● CamReader – класс наследник класса ReaderBase , реализующий чтение из веб-камеры и ip -камеры. Хранит последнее прочитанное изображение в качестве защиты от потери кадров.
● VideoReader – класс наследник класса ReaderBase , реализующий чтение видеофайлов.
● ImageReader – класс наследник класса ReaderBase , реализующий чтение изображений.
Для работы в реальном времени можно либо считывать по одному кадру, либо больше, но быть готовым, что видеопоток будет отставать на какое-то время. Возвращает изображение в формате numpy.ndarray.
1.2.5 Диаграмма классов пакета model
Для реализации компонентов model необходимо, чтобы передаваемые модели имели соответствующий формат входных и выходных данных. Для соответствия этому формату необходимо переопределить метод forward для класса Module из фреймворка PyTorch пакета nn. Структура классов изображена на рисунке 1.5.
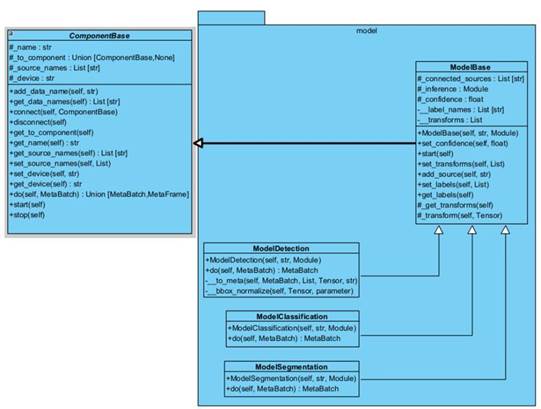 |
Рисунок 1.5 - Диаграмма классов пакета model
● ModelBase – базовый класс компонентов моделей, содержащий поля и методы, необходимые всем типам моделей компьютерного зрения.
● ModelDetection – компонент, который на вход принимает модель детекции типа torch.nn.Module , метод forward , которой возвращает словарь с ключами boxes , labels , scores , которые хранят тензор ограничивающих рамок, численное значение метки класса и уверенности в ответе соответственно.
● ModelClassification – компонент, который на вход принимает модель типа torch.nn.Module , метод forward , которой возвращает тензоры вероятностей принадлежности изображения к классу.
● ModelSegmentation – компонент, который на вход принимает модель типа torch.nn.Module , метод forward которой возвращает тензор масок равный числу классов, где каждая маска отвечает за обнаружение класса соответствующего порядку расположения классов.
1.2.6 Диаграмма классов пакета handler
Пакет handler на рисунке 1.6 реализует компоненты постобработки и анализа данных.
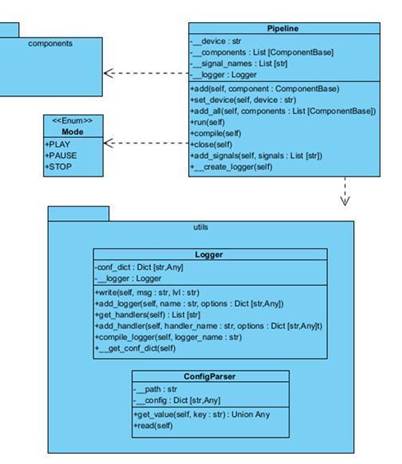 |
Рисунок 1.6 - Диаграмма классов пакета handler
● Counter – компонент, считающий количество объектов, пересекших выделенную зону. Объекты могут считать, как с учётом наличия уникального идентификатора, так и без.
● Filter – компонент, удаляющий переданные ему классы из предсказания. Что позволяет переиспользовать модели, убирая ненужные предсказания. Что позволит брать готовые модели на огромное количество классов и просто указывать, как метки мы хотим идентифицировать.
1.2.7 Диаграмма классов пакета painter
На рисунке 1.7 изображен пакет диаграммы классов painter , их задача
отрисовка
приведение изображение к определенному формату.
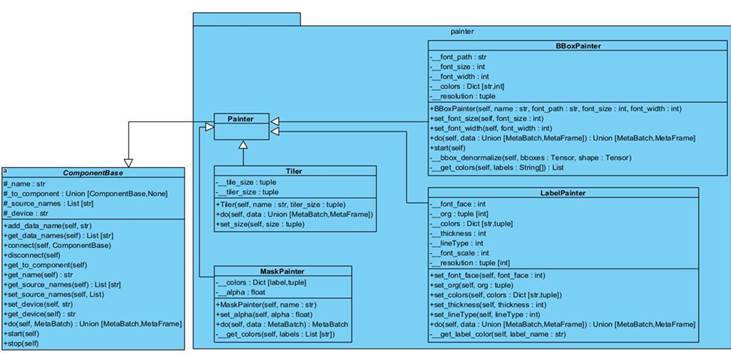
Рисунок 1.7 – Диаграмма классов пакета painter
● Painter – абстрактный класс, имеющий значение логического деление на подгруппу.
● LabelPainter – класс, отвечающий за написание класса, полученного из моделей классификации на изображение. По умолчанию предсказанный класс пишется вверху слева от кадра, но возможно пользовательская настройка.
● BBoxPainter – класс, отвечающий за нанесение ограничивающих рамок и класса объектов, полученных из моделей детекции на изображение.
● MaskPainter – класс, отвечающий за нанесение масок, полученных из моделей сегментации, на изображение.
● Tiler – класс, отвечающий за объединение изображений, полученных из разных источников, в один кадр. Таким образом, появляется возможность записи или вывода результатов всех видеопотоков в один экземпляр.
Первые три предыдущие компонента поддерживают возможность настройки уникального цвета для каждого класса, если параметр не передан, то компоненты сами генерируют уникальный цвет.
1.2.8 Диаграмма классов пакета outer
За вывод результата отвечают компоненты пакета outer , представленные на рисунке 1.8.
Рисунок 1.8 - Диаграмма классов пакета outer
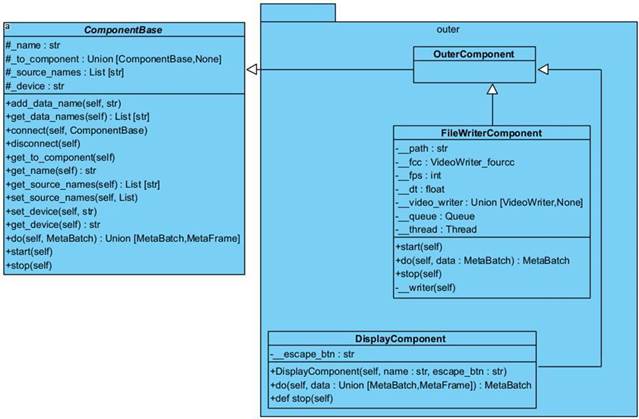 |
● OuterComponent – абстрактный класс, отвечающий за логическое деление компонентов пакета outer на подгруппу. Переопределяет параметр _ source_names , который служит компонентам для указания с какими потоками видеоданных они работают. В компонентах, наследующихся от OuterComponent , это значение будет равно списку из одного элемента tiler , он указывает, что результат вывода будет осуществлен лишь для изображений, полученных путем обработки компонентом Tiler.
● FileWriterComponent – класс, отвечающий за запись результата в видеофайл. Компонент в отдельном потоке считывает данные очереди для записи, сделано это для того, чтобы была возможность равномерной записи видеопотока в файл.
● DisplayComponent – класс, отвечающий за вывод результата на экран.
1.2.9 Диаграмма классов pipeline
Для того, чтобы связать все компоненты в одну цепочку, а также задавать им цикличный вызов метода do во всех компонентах необходим контейнер, структура которого представлена на рисунке 1.9.
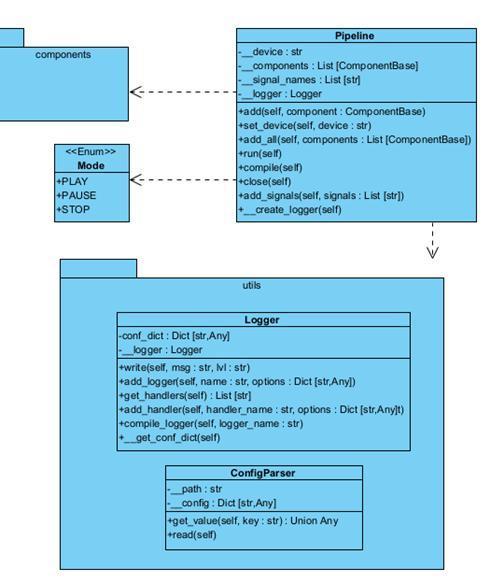 |
Рисунок 1.9 – Диаграмма классов pipeline
● Pipeline – класс, отвечающий за проверку, построение, работу и закрытие компонентов. Он передает данные между компонентами, а также считывает сигналы, такие как Mode.
● Mode – класс перечисления, нужен для задания сигнала состояния, эти сигналы передают компоненты, а pipeline считывает и обрабатывает.
● Logger - класс логирования, позволяет выводить информации о состоянии в консоль и файл, а также указывать уровни и настраивать встроенный Logger из модуля config языка Python.
Пример конвейера в рамках архитектуры
На рисунке 1.10 показан пример конвейера в рамках готового приложения
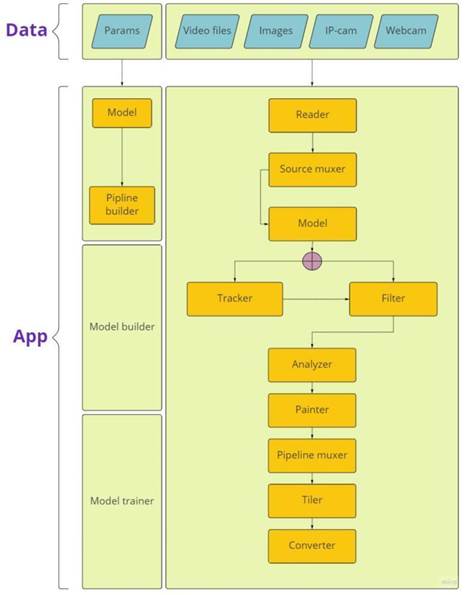 |
Рисунок 1.10 - Архитектура конвейера в приложении
Итоговый список используемых технологий
На основе архитектуры и требований был составлен список технологий.
1. язык программирования Python 3.7;
2. фреймворк opencv-python 4.5.5.64;
3. фреймворк pytorch 1.11.0;
4. часть пакета pytorch проект torchvision 0.12.0;
5. библиотека numpy 1.21.5;
6. unittest 26.4
7. Git
8. github.com
1.3 Обучение алгоритмов
Обучение происходит с помощью переключения режимов работы объекта класса Pipeline и передачи в него объектов DataLoaderMuxer вместо объектов на основе ReaderBase . Архитектура данного класса проиллюстрирована на рисунке 1.11.
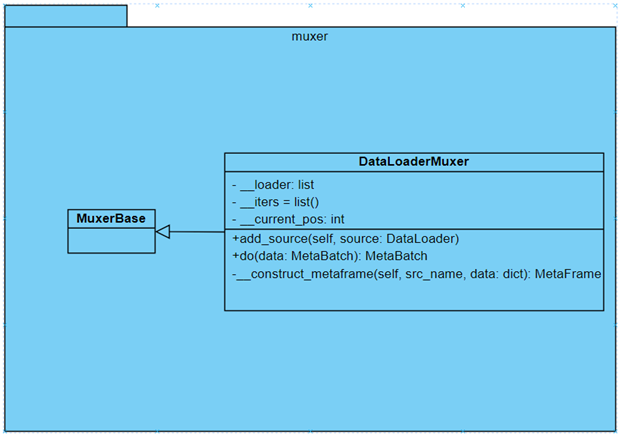
Рисунок 1.11 - Архитектура класса DataLoaderMuxer
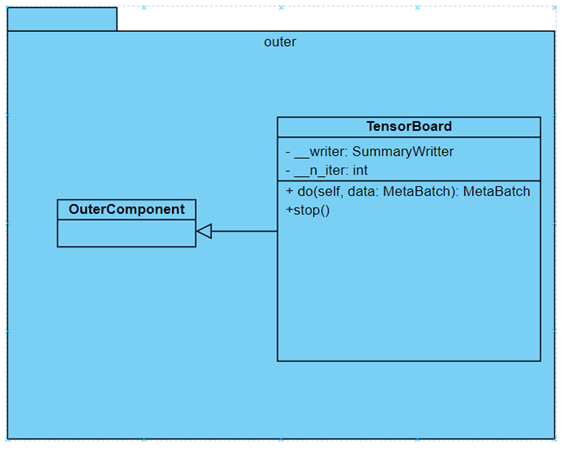
Также был реализован дополнительный класс для вывода метрик при
обучении. Для этого использовался инструмент
TensorBoard.
Архитектура класса показана на рисунке 1.12.
Рисунок
1.12 - Архитектура класса
TensorBoard
Пример графиков и интерфейса показан
на рисунке 1.13.
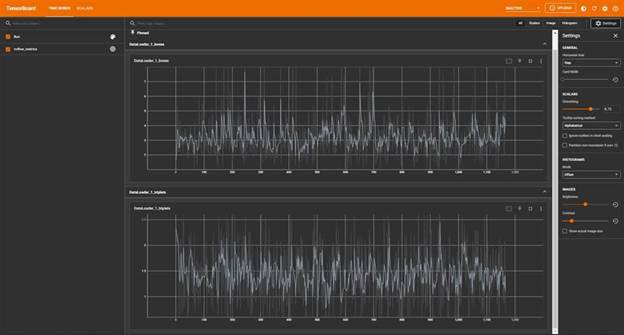
Рисунок 1.13 - Панель отображения метрик при процессе обучения.
1.4 Оптимизация скорости работы алгоритмов
Благодаря тому, что фреймворк реализован блочно, скорость работы алгоритмов не зависит от фреймворка. Скорость обработки самим фреймворком этих алгоритмом занимает тысячные секунды.
1.5 Тестирование качества, скорости, отказоустойчивости системы
1.5.1 Скорость работы
Для проверки скорости работы проведено сравнение с фреймворком, частично выполняющего те же самые задачи. Фреймворк DeepStream [1] от компании Nvidia позволяет строить конвейеры с различными нейронными сетями. Для тестирования были выбраны различные архитектуры для задач классификации, детекции и сегментации. Результаты тестирования можно посмотреть на рисунке 1.14.
Рисунок
1.14 - Диаграмма сравнения скорости работы функционально идентичных конвейеров
фреймворков
DeepStream
и
cvflow
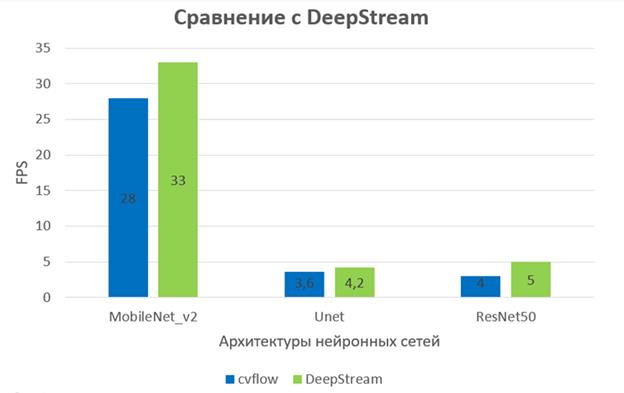
Учитывая, что DeepStreeam написан на компилируемом языке C , но при этом не соответствует некоторым требованиям для наших целей, результат можно считать хорошим, поэтому производительность полученного фреймворка считаем приемлемыми.
Также на примере архитектуры ResNet 50 были протестированы скорости выполнения конвейеров для задач классификации, детекции и сегментации для 1 или нескольких потоков. Результат можно увидеть на таблице 1.1. По этим результатам можно увидеть влияние количества источников на скорость работы конвейеров.
Таблица 1.1 - Таблица влияния количества источников для основных задач cv.
|
Компоненты |
Кадров в секунду |
|
Resnet 50 + Компонент сегментации для 1 видеопотока. Разрешение 240 на 320 |
3 fps |
|
Resnet 50 + Компонент сегментации для 2 видеопотока. Разрешение 240 на 320 |
1.6 fps |
|
Resnet 50 + Компонент детекции для 1 видеопотока. Разрешение 240 на 320 |
4 fps |
|
Resnet 50 + Компонент детекции для 2 видеопотока. Разрешение 240 на 320 |
2.3 fps |
|
Resnet 50 + Компонент классификации для 1 видеопотока. Разрешение 240 на 320. Результат на рисунке 3.10 |
9 fps |
|
Resnet 50 + Компонент классификации для 2 видеопотока. Разрешение 240 на 320 |
6 fps |
Можно заметить, что скорость уменьшается в диапазоне от 1.5 до 2 раз. Таким образом появляется задача оптимизации влияния количества источников на скорость работы.
1.5.2 Отказоустойчивость
На данный момент задача отказоустойчивости заключается в непредвиденных сбоях в работе компонентов конвейера. Для того, чтобы при постоянной работе системы не было поломок, каждый компонент сохраняет информацию, поступившую до обработки в текущем компоненте. Далее, если внутри компоненты произойдет сбой, то в следующую компоненту пойдут данные, сохраненные до поломки, таким образом конвейер не перестанет работать, а продолжит функционировать. Если откажет источник ввода видеопотока, то обработку проходят последние успешно сохраненные кадры. Конвейер не станет запускаться только в том случае, когда ни один из источников ввода не работает успешно.
1.5.3 Качество
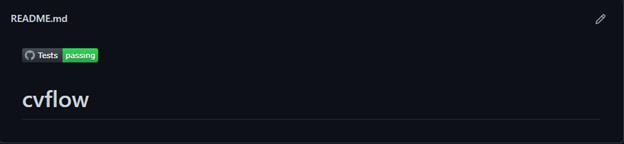
Для постоянной проверки качества, код библиотеки был покрыт unit тестами. Проверены входные и выходные данные для каждого компонента, а также граничные условия. Для поддержания корректности работы была написана конфигурация, которая автоматически запускает тестирование библиотеки на github , тем самым указывая на работоспособность библиотеки. На рисунке 1.15 показано, как выглядят полностью пройденные тесты, указывая на качество последней версии.
Рисунок 1.15 - Файл ReadMe , указывающий на полностью пройденные тесты на github
 |
1.6 Поиск ошибок и некорректной работы
В качестве методологии разработки фреймворка была использована спиральная модель. Для поиска ошибок было использовано unit тестирование, с помощью которого были найдены и исправлены некоторые ошибки. Часть ошибок была найдена при имплементации новых алгоритмов в фреймворк, но была также успешно исправлена. Далее, по мере работы и развития фреймворка все ошибки будут исправляться таким же образом.
1.6.1 Ошибка распознавания объектов в сложных условиях
Ошибка: Алгоритм по детекции людей и автомобилей в некоторых случаях распознает один объект, как несколько, либо не распознаёт совсем, если детекция производится в сложных погодных условиях.
Решение: Дообучить модель на данных с сложными погодными условиями, а также аугментировать данные путём искусственного добавления шума на кадрах.
1.6.2 Ошибка детекции дефектов на поверхности с текстом
Ошибка: На поверхностях, имеющих текст, алгоритм распознает текст, как дефект.
Решение: Дообучить модель на поверхностях с текстом и изменить способ поиска ограничивающих рамок.
2. Поиск, сбор, анализ, разметка и обогащение данных
2.1 Создание требований по данным для обучения алгоритмов
При реализации системы стремимся создать универсальную библиотеку, которая будет применима не только к узкому классу задач, на решение которых была обучена, но и к новым задачам, что учитывалось в требованиях к данным.
● Для тренировки алгоритмов распознавания положения объекта требуется набор, содержащий минимум 5000 фотографий предметов, сделанных с двух камер. К нему должна быть доступна разметка в виде карт глубины или карт разницы.
● Для оценки качества распознавания положения объекта в пространстве необходимо минимум 5 коротких видео с одной камеры, а лучше с нескольких, где в камеру показывают “шахматную доску” фиксированного размера для калибровки камеры. Необходимо определять, где находится объект, поэтому двигаться он должен рядом с линейкой.
● Для тренировки и тестирования алгоритмов нахождения дефектов требуются наборы фотографий разных поверхностей, в том числе дерева, металла, бетона и мрамора.
● Для решения задачи распознавания номера объекта необходимо найти/создать соответствующий набор данных. Он должен представлять собой аннотированные изображения (либо кадры видео). Аннотация должна включать в себя информацию о локализации номеров (координаты прямоугольника минимальной площади, содержащего номер), а также наборы символов, характеризующие сами номера. Кроме этого, нужно учесть географическую привязку, то есть получить набор данных с изображениями автомобилей на русских номерах.
● Для тренировки распознавания номеров автомобилей требуется размеченный набор минимум из 10000 изображений. Для распознавания номеров остальных объектов планируется применить дообучение, поэтому требуется 100-500 изображений объектов каждой категории (вагоны, бруски металла, посылки). На объектах номер может располагаться как на специальных табличках, так и на бумаге, а может быть написан краской на самом объекте.
● Для определения размеров объектов требуется разметка изображений. В данном разделе предполагается определение размера кузова машины, что для дообучения существующих моделей требует минимум по 25 изображений каждой категории.
2.2 Используемые наборы данных
В проекте выделено несколько основных задач: определение положения объектов в пространстве, распознавание дефектов, распознавание номеров объектов, анализ перемещения объектов, определение размеров объектов. По всем направлениям был произведен поиск открытых наборов данных, его результаты представлены в таблице.
Ссылки на используемые наборы данных будут представлены в разделах отчета, соответствующих задачам.
Таблица 2.1 - Наличие в открытом доступе данных по задачам системы необходимость сбора и разметки. Цветом отмечена степень необходимости сбора данных.
|
Задача |
Существующие данные |
Количество и оценка |
Сбор |
|
Определение положения объектов в пространстве |
Есть только 2 датасета и те не по задаче. |
2 плохих |
Обучающий и тестовый |
|
Распознавание дефектов |
Есть наборы фотографий металла, бетона и ткани и других поверхностей с дефектами и без. |
38, много |
Не нужен |
|
Распознавание номера объекта |
Для распознавания номеров автомобилей есть данные. Других объектов – нет. |
2 + 2, частично есть |
Обучающий и тестовый для не автомобилей |
|
Анализ перемещения объектов |
Видео в открытом доступе. Трансляции на Youtube с камер видеонаблюдения. Набор данных KITTY. |
2 |
Не нужен |
|
Определение размеров объектов |
Достаточных данных для определения размеров т/с и для детекции предметов на конвейере нет. |
2 частично |
Обучающий и тестовый по разным задачам |
2.3. Поиск и выбор оптимальных параметров камер
В рамках реализации основных алгоритмов библиотеки использовались различные виды камер и объективов с фокусным расстоянием от 2 до 85мм.
Кроме того, команда принимала участие во множестве других проектов, на базе которых строились рекомендации по оптимальному выбору качества, fps , и других параметров видео. Согласно Календарному плану в рамках Договора выполнялась съёмка при различных условиях и различных объектов, как движущихся, так и стационырных (освещённость, погодные условия, различные материалы, номера и тд). Камеры машинного зрения имели разрешения от VGA до 86 Мп для строчно-кадровой или 4 K для однострочной развертки — и снимали до 200 кадров в секунду. Например, освещенность в ясный солнечный день имела значения от 32 тысяч лк до 130 тысяч лк, в очень пасмурный день - 100 лк, а ночью — 1 лк. Интерфейсы передачи видео также зависели от определённой задачи, в ходе работ использовались USB 3 Vision , GigE Vision , Camera Link.
2.3.1 Анализ и спецификация существующего видео оборудования, которое наилучшим образом будет подходить для наилучшего качества работы алгоритмов
В ходе произведённых работ и тестирования алгоритмов было установлено, что наилучшим для работы алгоритмов будет использование камеры с фокусным расстоянием в основном 3-4 мм, а для задач компьютерного зрения необходимое фокусное расстояние мм.
2.4 Формирование заданий на сбор и разметку данных
В результате поиска в сети Интернет были найдены данные для обучения моделей не для всех задач, решаемых в библиотеке. Соответственно, были сформированы задания на сбор достаточного количества данных по задачам:
Определение положения объектов в пространстве – синтетический набор данных из 10000 пар изображений, небольшой набор реальных видео.
Распознавание номера объекта – 100 фотографий вагонов с отмеченным номером, 100 фотографий разнородных объектов с номерами для тестирования алгоритмов.
Определение размеров объектов – 800 фотографий машин для классификации типа кузова.
Классификация категории объекта – синтетический набор данных из 2500 изображений, состоящий из набора в 500 фонов и размещенных на них деревянных, металлических и бетонных объектов.
В рамках адаптации алгоритмов к сложным условиям среды произведен сбор данных по перемещению транспорта в сложных погодных условиях и в темное время суток.
2.5 Проведение дополнительных работ по сбору данных (в случае их отсутствия организация специальных съемок на различных производствах).
По результатам поиска данных в открытых источниках было собрано и размечено 8 наборов изображений, их описание и размер представлены в таблице 2.2. Более подробно собранные и размеченные данные будут описаны в разделах, соответствующих задачам. На этап 2 намечена задача по определению перемещений в ложных условиях, уже начата разработка алгоритмов по этой теме и собран набор виде №5.
Таблица 2.2 - Описание собранных и размеченных наборов данных.
|
№ |
Описание |
Число объектов |
Пример изображения |
|
1 |
Фотографии вагонов для распознавания их номеров с разметкой номеров (баундинг бокс номера + цифры/буквы) – сделаны участником. |
40 + будет собрано еще 60 |
|
|
2 |
Фотографии вагонов для распознавания их номеров с разметкой номеров (баундинг бокс номера + цифры/буквы) – из открытых видео. |
1151 |
|
|
3 |
Фото машин для классификации типа кузова (и определения его высоты). Классы: легковая, кроссовер, фургон, автобус, грузовик, велосипед, другое т/с, человек. |
802 |
|
|
4 |
Синтетический набор изображений для определения положения объектов в пространстве и расстояний можду ними. |
10000 |
|
|
5 |
Набор видеозаписей движения небольших объектов. |
10 видео по 15-20 секунд |
|
|
6 |
Набор видеозаписей автомобильных дорог в разное время суток. Будет использован позже, при адаптации алгоритмов к сложным условиям среды. |
10 видео по 2 минуты |
|
|
7 |
Синтетические изображения производственных объектов/деталей с номерами. |
100 |
|
|
8 |
Синтетические композиции изображений поверхностей: дерево/металл/бетон. |
2500 |
|
|
9 |
Синтетические изображения с текстом, похожим на номер на фоне производственного помещения |
10000 |
|
|
10 |
Изображения объектов с номерами на них (металл, кирпич, бумага, пластик, стекло) |
1210 |
|
|
11 |
Фотографии автомоблей в условиях плохого освещения, заснежности, дождя) |
357 |
|











3. Выбор подходов и алгоритмов
● Определение положения объектов в пространстве – данную задачу можно решить с использованием специализированных камер, способных находить глубину объектов, с помощью одной, двух или многих фотографий с разных ракурсов. Специализированные устройства не рассматриваются в рамках данной библиотеки, а сбор более двух потоков – слишком затратное и вряд ли будет реализовано. Кроме того, с помощью изображения с двух камер можно достичь большей точности построения карты глубины, чем с одной, так как нейронная сеть получает больше информации. Исходя из вышеперечисленного, для определения положения объектов в пространстве было выбрано построение карты глубины по двум видеопотокам ( depth from stereo), сравнение конкретных сетей представлено в разделе 4.
● Распознавание дефектов – находить дефекты планируется на разных поверхностях, в том числе неизвестных нейронной сети. Планируется, что пользователь библиотеки загрузит в данный модуль изображения с дефектами на них, то есть возникает задача обучения с одного взгляда ( one-shot learning ). Эту задачу решают с помощью сиамской нейронной сети [18], которая и была реализована на данном этапе. Для выделения признаков поверхности использовалась предобученная нейронная сеть VGG 19, известная своей способностью к извлечению признаков из изображений [19].
● Распознавание номера объекта – алгоритм распознавания номеров автомобилей по видеопотоку. Такой алгоритм состоит из двух частей: часть детекции (позволяющая локализовать номер на кадре) и часть распознавания (генерирующая набор символов по части кадра). Кроме этого, важно, чтобы алгоритм позволял делать распознавание номеров автомобилей на дорогах общественного пользования в реальном времени. Был проведен обзор литературы и выбрана подходящая модель, подробнее в разделе 5.
● Анализ перемещения объектов – для решения данной задачи нужно найти объект на кадре видео, то есть решить задачу детекции. Так как детектировать объекты требуется в реальном времени, то для реализации должен быть использован одностадийный детектор. На момент окончания работ по первому эта самым быстрым и оптимизированным для реальных приложений было модель YOLOv 5 [15], которая и была выбрана для решения данной задачи. Чтобы анализировать перемещения объектов, требовалось их отследить, на первом этапе был реализован алгоритм корреляционного мультитрекинга [16], далее планируется использовать алгоритм DeepSORT [17].
● Определение размеров объектов – по итогам разработки предыдущего модуля, описанного в главе 6, была получена система для анализа перемещения объектов, однако этот модуль не позволяет получать информацию о самих объектах. Вместе с тем, наиболее важным применением этой системы в промышленных условиях является именно анализ передвижения различных транспортных средств, поэтому в рамках системы был также реализован алгоритм для определения размеров кузовов транспортных средств. Второй подзадачей, выделенной в данном направлении, стала гранулометрия. Подробнее в разделе 7.
3.1. Формирование заданий на реализацию отдельных модулей
По результатам выбора подходов для решения задач библиотеки было сформировано задание на реализацию модулей:
● Разработка и имплементация алгоритмов определения расстояний, геометрических характеристик объектов – Крашенинников Егор Иванович
● Разработка и имплементация алгоритмов распознавание дефектов и прочих образований на материале (металл, дерево, пластик, пленка на жидкости) – Крашенинников Егор Иванович
● Разработка и имплементация алгоритмов захвата и подсчета объектов – Румянцева Мария Юрьевна
● Разработка алгоритмов определения размеров (распределений по размерам) объектов различной природы (руда на конвейере, люди в очереди, транспортный средства в потоке и т.д.) – Румянцева Мария Юрьевна
● Разработка и имплементация алгоритмов распознавание положения объекта (детали производственного оборудования, человека, машины) в пространстве – Румянцева Мария Юрьевна
● Разработка и имплементация алгоритмов классификации транспортных средств (категории объекта (тип транспортного средства, металла, дерева, и других материалов)) – Орехов Семен Дмитриевич
● Анализ перемещения объектов (людей, машин и других) в пределах установленной области – Орехов Семен Дмитриевич
● Разработка и имплементация алгоритмов распознавания номеров (автомобиля, вагона поезда, других объектов на производстве или в городской среде), номеров произвольной формы, различных шрифтов, маркировок, QR и штрих-кодов, надписей в условиях различной зашумленности и различных алфавитов – Новгородцев Никита Павлович
3.2. Создание требований по данным для обучения алгоритмов
● Разработка и имплементация алгоритмов определения расстояний, геометрических характеристик объектов – 10000 синтетических изображений и 10 видеозаписей.
● Разработка и имплементация алгоритмов распознавание дефектов и прочих образований на материале (металл, дерево, пластик, пленка на жидкости) – 5000 фотографий различных поверхностей с дефектами и без, обязательно дерево и металл.
● Разработка и имплементация алгоритмов захвата и подсчета объектов – набор из 10 видеозаписей улиц с транспортом и людьми для тестирования алгоритмов.
● Разработка алгоритмов определения размеров (распределений по размерам) объектов различной природы (руда на конвейере, люди в очереди, транспортный средства в потоке и т.д.) – 10 видеозаписей
● Разработка и имплементация алгоритмов распознавание положения объекта (детали производственного оборудования, человека, машины) в пространстве – 10000 синтетических изображений и 10 видеозаписей.
● Разработка и имплементация алгоритмов классификации транспортных средств (категории объекта (тип транспортного средства, металла, дерева, и других материалов)) – 1000 изображений транспортных средств различных категорий.
● Анализ перемещения объектов (людей, машин и других) в пределах установленной области – набор из 10 видеозаписей улиц с транспортом и людьми для тестирования алгоритмов.
● Разработка и имплементация алгоритмов распознавания номеров (автомобиля, вагона поезда, других объектов на производстве или в городской среде), номеров произвольной формы, различных шрифтов, маркировок, QR и штрих-кодов, надписей в условиях различной зашумленности и различных алфавитов – 10000 изображений с номерами транспортных средств, 1000 изображений номеров вагонов, 1000 изображений указанных надписей.
4. Алгоритмы определения положения объектов в пространстве и расстояния между ними
Создание алгоритмов определения взаимного положения объектов нескольких в пространстве с высокой точностью по трём осям ( X-Y-Z ) и расчёта расстояния между ними. Для определения перемещения оси глубины выбрано использование стереозрения, т.е. одновременной съёмки видео с двух камер и построение карты глубины. На основе знания расстояний до объектов и характеристик камеры (фокусное расстояние, размер матрицы, разрешение итогового изображения) возможно определение точного расстояния между несколькими выбранными объектами с помощью триангуляции.
Исследование источников показало, что существующие модели определения расстояний в основном используются для автоматического управления автомобилями и рассчитаны на определение расстояния до больших объектов (автомобиля, дерева, человека), соответственно имеют допустимую для этих случаев погрешность 0.05-0.3 метра на расстоянии 4 и более метров, имеют значительную погрешность при определении близких объектов и не всегда учитывают мелкие объекты.
Реализован программный модуль библиотеки, предназначенный для определения расстояния до заданных пользователем объектов для последующего расчёта расстояния между ними (в метрических величинах) относительно расстояния до объектов. Основным преимуществом разработанного программного модуля является спецификация на определении расстояния до небольших произвольных объектов, на которых не производилось предварительное обучение, возможность быстрого масштабирования.
Данный функционал реализован благодаря использованию стерео-зрения, т.е. съемки с двух камер одновременно. Системы, работающие с использованием одной камеры, определяют расстояние до известных объектов, на которых модели были обучены. Система, работающая с использованием двух камер, реагирует на смещение объектов относительно друг друга, что позволяет отслеживать расстояние до произвольных объектов. Особенностями использования технологии является:
● необходимость использования двух одинаковых по характеристикам камер;
● необходимость калибровки камер для построения карты глубины;
● сложность разметки данных.
Для калибровки камер, т.е. получения внутренних параметров (фокусного расстояния, оптического центра, коэффициента радиального искажения объектива) и внешних параметров (поворотом и смещением) камеры относительно некоторой мировой системы координат) разработан программный модуль средствами открытой библиотеки OpenCV . Для калибровки необходимо предоставить снимки с используемых камер с изображением шахматной доски фиксируемого размера. Данное действие позволяет получить параметры для уточнения дальнейшего определения расстояния. Также из изображения получаются данные о матрице камеры, необходимые для преобразования расстояния, измеряемого в пикселях, в метрические величины.

Рисунок. 4.1 – Визуализация калибровки камеры с помощью шахматной доски.
Исследование литературы позволило выбрать несколько открытых моделей стерео зрения в качестве базы. В качестве критерия выбора использовалась метрика 3- px error , т.е. процент пикселей, более чем на 3 пикселя удалённых от своего целевого положения [1]. По такому критерию были отобраны модели MobileStereoNet [2] и CDN-GA-Net [3]. MobileStereoNet реализует легковесные блоки на основе MobileNet , адаптируя их к задаче стерео зрения. CDN-GA-Net применяет к задаче стерео-зрения функцию потерь на основе расстояния Вассерштейна [4]. Модели протестированы на снятом датасете с двух камер, результат которого показал необходимость дообучения на собственном для получения приемлемых результатов для небольших произвольных объектов.

Рисунок. 4.2 – Результат предсказания без дообучения
Существуют несколько датасетов для стерео-зрения. Самыми известными из них являются: датасет KITTI [1], представляющий собой набор с уличных съемок окружающей среды, предназначающийся для использования в первую очередь в задачах, связанных с беспилотными автомобилями; синтетический датасет Sceneflow [5], представляющий собой набор созданных в среде 3 D -моделирования Blender объектов. Исследование последнего показали, что его составляют несколько частей: модели мультфильмов, аналогичные KITTI уличные сцены и случайные объекты, помещенные в виртуальную среду. Более близким к требуемой задаче является датасет Sceneflow , поэтому было принято решение о создании аналогичного датасета, соответствующего целевой задаче.
Для сбора синтетического датасета была выбрана среда разработки blender , в которую были помещены более 20 моделей инструментов, устройств и бытовых вещей. Размер объектов был нормирован до 1 метра в физическом аналоге. На один кадр помещается от 3 до 8 случайных объектов, расположение, угол поворота и цвет объектов так же случайно. В качестве фона выбраны фотографии промышленных помещений. Объекты, помещенные на изображения, имеют размер от 10 до 50 сантиметров и расположение на расстояние 0.5-2 метра от камеры. Далее карта глубины, полученная с помощью blender , была переведенаа в карту разницы по формуле:
![]() ,
,
где disparity – целевая переменная значения разницы между изображениями, baseline – константа, коэффиециент трансляции координат изображения в координаты реального мира, focal length – фокусное расстояние, depth – глубина.
|
|
|
|



Рисунок. 4.3 – Пример генерации изображений и карты разницы.
Было сгенерировано 1000 изображений со случайными объектами. На данном датасете было произведено дополнительное обучение моделей с последующим тестированием. Задачей тестирования является сопоставление полученных расстояний до объектов с помощью моделей с реальными расстояниями.
|
|
|
|
|
|
|
|






Рисунок. 4.4 - Пример результатов работы дообученной модели MobileStereoNet
|
|
|
|
|
|
|
|






Рисунок. 4.5 - Пример результатов работы дообученной модели CDN - GaNET
В результате дообучения видно, что целевые объекты имеют чёткие контуры и точно выделяются на фоне окрущающей среды. Снимаемые объекты находятся на расстоянии 50-70 сантиметров от камеры и имеют размеры 5-20 сантиметров. Последним этапом вычисления является перевод значение полученной разницы между кадрами в метрические величины по формуле
![]() ,
,
где disparity – переменная значения разницы между изображениями, baseline – константа, коэффициент трансляции координат изображения в координаты реального мира, focal length – фокусное расстояние, depth – целевая переменная расстояния до объекта. На основе этого были полученные следующие значения расстояния до объектов – таблица 4.1:
Таблица 4.1 – Полученные значения расстояния до объектов
|
№ |
Модель |
Высота объекта |
Расстояние до объекта |
Реальное расстояние до объекта |
Ошибка |
|
1 |
MobileStereoNet |
0.1 м |
0.63 м |
0.6 м |
30 мм |
|
2 |
MobileStereoNet |
0.2 м |
0.64 м |
0.6 м |
40 мм |
|
3 |
MobileStereoNet |
0.1 м |
0.68 м |
0.7 м |
20 мм |
|
4 |
MobileStereoNet |
0.1 м |
0.35 м |
0.25 м |
100 мм |
|
5 |
CDN-GaNET |
0.1 м |
0.62 м |
0.6 м |
20 мм |
|
6 |
CDN-GaNET |
0.2 м |
0.56 м |
0.6 м |
40 мм |
|
7 |
CDN-GaNET |
0.1 м |
0.75 м |
0.7 м |
50 мм |
|
8 |
CDN-GaNET |
0.1 м |
0.4 м |
0.25 м |
150 мм |
В результате тестирования моделей видно, что ошибка определения расстояния для объектов, расположенных в 0.6-0.7 метрах от плоскости камеры составляет менее 7% относительно расстояния (0.02-0.03 метра). Значительная ошибка формируется для объектов, расположенных в пределах 0.5 метров до камеры, что может свидетельствовать о недостаточном количестве аналогичных данных в обучающем датасете.
Расстояние между объектами таким образом определяется по формуле:
![]() , L
=
Lpx*baseline
, L
=
Lpx*baseline
где l
– искомое расстояние между объектами в сантиметрах,
d
– расстояние до объектов,
L
– расстояние между объектами в м,
f
– фокусное расстояние,
baseline
– количество
px
в одном метре.
Данные о расстоянии до объектов получены с помощью съемки с двух камер, отслеживаются
на изображении с левой камеры, так как предсказывается глубина изображения с
левой камеры, согласно датасету
Sceneflow
[5]. Два объекта выделяются с помощью выделения пользователем и рассчитывается
расстояния между крайней правой точкой левого объекта и крайней левой точкой
правого объекта.

Рисунок. 4.6 - Пример расчёта определения расстояния в пикселях между двумя объектами
Таблица 4.2 – Результаты испытаний
|
№ |
Расстояние до объектов |
Предсказанное расстояние между объектами |
Реальное расстояние между объектами |
Ошибка |
|
1 |
70 см |
113 мм |
101 мм |
12 мм |
|
2 |
70 см |
93 мм |
101 мм |
7 мм |
|
3 |
60 см |
105 мм |
100 мм |
5 мм |
|
4 |
60 см |
94 мм |
100 мм |
6 мм |
|
5 |
60 см |
95 мм |
100 мм |
5 мм |
Таким образом расстояние между объектами можно определить с точность до 10 мм на расстоянии до 0.7 м.
Данные результат является допустимым для съемки объектов с дальнего расстояния с учётом характеристик камеры и погрешности. Полученный результат является результатом в сложных условиях, осуществлялась съемка небольших объектов на непрофессиональную камеру с достаточно низким разрешением. При этом производилась обработка изображений со сниженным качеством для убыстрения работы. При использовании специализированных камер и мощностей, которые позволят предсказывать расстояния для более детализированных изображений и съемки с расстояния, не превышающего 35 см без оптических искажений (что наблюдается в непрофессиональной оптике) будет достигнута точность, заявленная в задании.
Условия съемки, позволяющие реализовать определение расстояния с точностью до 5 мм:
* расстояние до объектов: < 35 см
* освещение: объекты дополнительно подсвечены в случае отсутствия дневного света или его недостатка.
* разрешение камеры: не менее 18 МП, предпочтительно использование профессиональной аппаратуры (не веб-камеры, не камеры мобильного телефона).
Испытания в условиях, приближенных к идеалу (определение размера объекта) – рисунок 4.7
|
|
|
|
|
|
|
|






Рисунок. 4.7 – Испытания в условиях, приближенных к идеалу (определение размера объекта)
Таблица 4.3 – Результаты испытаний в нормальных условиях
|
№ |
Расстояние до объектов |
Предсказанный размер объекта (расстояние между крайними точками) |
Реальный размер объекта |
Ошибка |
|
1 |
30 см |
153 мм |
150 мм |
3 мм |
|
2 |
35 см |
149 мм |
150 мм |
1 мм |
|
3 |
25 см |
148 мм |
150 мм |
2 мм |
|
4 |
30 см |
104 мм |
100 мм |
4 мм |
|
5 |
35 см |
102 мм |
100 мм |
2 мм |
|
6 |
25 см |
97 мм |
100 мм |
3 мм |
Таким образом, при соблюдении условий, близких к идеалу, определение расстояния между точками (или объектами) будет осуществлено с точностью до 5 мм.
4.1. Тестирование, оптимизация алгоритмов
Осуществлено повышение точности и устойчивости работы алгоритмов в различных условиях с помощью замены стационарного фона на пары стерео-изображений. В сгенерированном на первом этапе наборе данных были использованы фоны без глубины (плоские картинки), на которую накладывались объекты только на изображении, но не на карте глубины. На этом этапе в наборе данных использовались изображения из открытых источников с картой глубины по всему помещению.
Использован набор данных Middlebury [2] , на который были наложены сгенерированные ранее объекты объекты. Обучение на таком наборе данных повысило качество распознавания на тестовых синтетических наборах данных, однако не улучшило на реальном наборе данных с небольшими объектам. Результат MobileStereoNet на синтетическом наборе данных представлен на рисунке 4.8. Результат на реальном наборе данных представлен на рисунке 4.9.


Рисунок 4.8 - Результаты построения карты глубины на синтетических изображениях.


Рисунок 4.9 - Результаты построения карты глубины на реальных изображениях.
С помощью дообучения модели, обученной на синтетическом датасете, на датасете Middlebury улучшилось качество распознавания мелких объектов, при этом фон по прежнему не учитывается (рисунок 4.10):



Рисунок 4.10 - результат Mobilestereonet на реальном датасете, снятом на стереокамеру.
Результат GAnet на реальном датасете (рисунок 4.11):


Рисунок 4.11 - результат GAnet на реальном датасете Middlebury , снятом на стереокамеру
Был осуществлено тестирование моделей на доработанной модели с учётом сложных условий для объектов на расстоянии 30-50 см (таблица 4.4):
Таблица 4.4 - результаты тестирования на дообученной модели.
|
№ |
Расстояние до объектов |
Предсказанное расстояние между объектами |
Реальное расстояние между объектами |
Ошибка |
|
1 |
30 см |
103 мм |
100 мм |
3 мм |
|
2 |
30 см |
95 мм |
100 мм |
5 мм |
|
3 |
50 см |
47 мм |
50 мм |
3 мм |
|
4 |
50 см |
97 мм |
100 мм |
2 мм |
|
5 |
50 см |
68 мм |
70 мм |
2 мм |
4.2. Проведение экспериментов и оценка качества разработанных моделей в различных условиях: время дня, внешние шумы (дождь, туман, снег), тестирование, оптимизация скорости работы алгоритмов
Разработан модуль для синтетического изменения условий стерео-изображений, включающий в себя – рисунок 4.12:
● Засвет
● Зашумленность
● Задымленность
● Туман
● Изменение яркости изображения (засвет, затемнение)
● Симуляция дождя
Сила каждой модификации может быть настроена.
|
|
|
|
Исходное изображение |
Дождь |
|
|
|
|
Туман |
Дым |
|
|
|
|
Шум (1) |
Шум (2) |
|
|
|
|
Шум (3) |
Засвет |
|
|
|
|
Пересвет |
Затемнение |










Рисунок 4.12 - Модуль для синтетического изменения условий стерео-изображений
Так как не существует стерео-датасета с небольшими объектами в сложных условиях, то было осуществлена обработка сгенерированных изображений созданными функциями. Для одного изображения применялось от 1 до 3 различных способов зашумления одновременно. Было осуществлено дообучение моделей, обученных на первом этапе,
Результаты на синтетическом датасете до дообучения:
MobileStereoNet (рисунок 4.13):


Рисунок 4.13 - результаты Mobilestereonet без дообучения
После дообучения:
MobileStereoNet (рисунок 4.14):


Рисунок 4.14 - результаты Mobilestereonet на синтетическом датасете после дообучения
GANet (рисунок 4.15):


Рисунок 4.15 - результаты GAnet на синтетическом датасете после дообучения
Полученные результаты тестирования на фотографиях:
MobileStereoNet (рисунок 4.16):


Рисунок 4.16 - результаты Mobilestereonet на реальном датасете после дообучения
GANet (Рисунок 4.17):


Рисунок 4.17 - результаты GAnet на реальном датасете после дообучения
После дообучения существенно увеличилось качество распознавания: при наличии условий, которые не закрывают объекты полностью (такие как блики) модель успешно работает с зашумленным изображением или с полупрозрачным затемнением/осветлением.
Проведена оценка работы на различных расстояниях до объектов(Таблица 4.5):
Таблица 4.5 - результаты работы на различных расстояниях
|
№ |
Расстояние до объектов |
Предсказанное расстояние между объектами |
Реальное расстояние между объектами |
Ошибка |
|
1 |
30 см |
102 мм |
100 мм |
3 мм |
|
2 |
40 см |
103 мм |
100 мм |
5 мм |
|
3 |
50 см |
97 мм |
100 мм |
3 мм |
|
4 |
60 см |
96 мм |
100 мм |
2 мм |
|
5 |
70 см |
95 мм |
100 мм |
2 мм |
|
6 |
80 см |
96 мм |
100 мм |
4 мм |
|
7 |
90 см |
95 мм |
100 мм |
5 мм |
|
8 |
100 см |
104 мм |
100 мм |
4 мм |
|
9 |
150 см |
110 мм |
100 мм |
10 мм |
|
10 |
200 см |
120 мм |
100 мм |
20 мм |
Таким образом, на расстояниях до одного метра достигается точность до 5 мм. На расстоянии менее 30 см невозможно осуществить построение карты глубины из-за технических особенностей камеры (межфокусное расстояние).
5. Разработка и имплементация алгоритмов распознавание дефектов и прочих образований на материале (металл, дерево, пластик, пленка на жидкости)
5.1 Дефекты на твердом материале
Разработаны алгоритмы, которые распознают дефекты на любом материале любых указанных пользователем видов. Планируется разработать и реализовать универсальный подход к поиску дефектов, то есть не по отдельной модели на каждый материал (дерево, сталь, бетон, мрамор и так далее, материалом множество), а одну модель для всех материалов. Качество, достигаемое такой моделью, будет меньше, но она не будет требовать дообучения под каждую конкретную задачу, хотя мы не исключаем эту возможность и добавляем соответствующий функционал.
Архитектура универсальной модели основана на классической сети SSD , признаки которой хорошо отражают паттерны на изображении. Вместо слоя классификации используется слой из векторов, как в сиамских нейронных сетях, что позволяет обучить модель на нескольких наборах данных сразу.
Были проанализированы методы нахождения дефектов и отобраны данные для этой задачи. Эксперименты проводились на фотографиях дерева [3] , металла [4] , мрамора [5] , статистики по этим наборам изображений представлены в таблице 5.1.
Таблица 5.1 - Статистики наборов данных с дефектами на материалах.
|
Набор данных |
Классы |
Число фото |
Пример |
|
Дерево |
6+1 (Без дефектов + 6 типов дефектов) |
6652 |
|
|
Сталь |
4+1
|
21500 |
|
|
Мрамор |
4+1 |
2937 |
|





Сеть была обучена на тренировочных частях данных о дефектах дерева и стали и протестирована на их тестовых частях по достигаемой точности (метрике mAP ). Также сеть была протестирована на разных типах поверхностей. Результаты представлены в таблице 5.2.
Таблица 5.2 – Тестирование на различных поверхностях
|
Данные |
mAP |
Пример изображения |
|
Дерево |
0.89 |
|
|
Сталь |
0.79 |
|
|
Мрамор |
0.77 |
|
|
Bottle |
0.7 |
|
|
Grid |
0.72 |
|
|
Zipper |
0.73 |
|
|
Cable |
0.72 |
|








Как можно видеть из таблицы, точность нахождения дефектов на дереве и металле больше 0,7, как и было заявлено. Дефекты на мраморе визуально похожи на дефекты на дереве, модель не обучалась на этом наборе изображений и никогда не видела поверхность мрамора, тем не менее смогла предсказать наличие и класс дефектов с точность более 0,7. На наборе изображений разнообразных предметов и поверхностей также достигается точность 0,7-0,8.
Ожидаемая точность по mAP достигнута даже на данных, которые алгоритм не видел, соответственно, цель достигнута.
Также алгоритм был был протестирован на изображениях, где условия были более сложные, чем в изначальных данных. Примеры работы представлен на рисунке 5.1.
|
|
|


Рисунок 5.1 - Пример работы модуля детекции дефектов.
5.2 Дефекты на жидкости
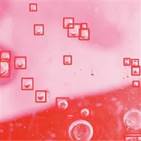
В рамках модуля обнаружения дефектов на жидкости рассмотрено три типа жидкостей: лакокрасочное покрытие, бензин и продукты флотации. Для первых двух типов жидкостей применялся детектор YOLOv 8, примеры представлены на рисунке 5.2. Для детекции пузырей, возникающих в процессе флотации использована модель U-Net , результаты представлены на рисунке 5.3 и подробнее описаны в разделе 14.
|
|
|
|
|
|
Рисунок 5.2.а. Детекция пузырей на лакокрасочном покрытии |
Рисунок 5.2.б. Детекция бензиновых пятен на жидкости |
||



|
|
|
|



Рисунок 5.3 - Детекция крупных пузырей в процессе флотации.
В таблице 5.3 представлены полученные результаты для трех типов жидкости. Кроме того, в таблице z указаны размеры обучающих выборок.
Таблица 5.3 - Значение метрик детекции для разных поверхностей и размер обучающей выборки (#объектов).
|
Жидкость |
#объектов |
Precision |
Recall |
mAP50 |
|
Бензин |
50 |
0,867 |
0,723 |
0,879 |
|
Лак |
50 |
0,795 |
0,832 |
0,844 |
|
Флотация |
100 |
0,762 |
0,641 |
0,773 |
6. Разработка и имплементация алгоритмов распознавания номеров (автомобиля, вагона поезда, других объектов на производстве или в городской среде), номеров произвольной формы, различных шрифтов, маркировок, QR и штрихкодов, надписей в условиях различной зашумленности и различных алфавитов
6.1. Номера автомобилей
Анализ различных источников в интернете позволил найти несколько соответствующих требованиям из раздела 2.1 наборов данных, из которых был выбран лучший [6] (с точки зрения качества разметки и количества примеров). В нем содержится 25000 изображений для обучения модели.
Алгоритмы распознования номеров, как правило, состоят из двух компонент – компоненты локализации (детекции), которая находит часть кадра, содержащую интересующую информацию, и компоненты генерации набора символов по выделенной области кадра.
Для выбора модели детекции был проведен анализ литературы, который позволил выявить лучшие модели в настоящее время с учетом скорости работы:
Таблица 6.1 – Анализ литературы
|
Модель |
Протестировано на COCO |
Комментарий |
|
Mask RCNN [11] |
box AP 39.8 |
Довольно старая, но проверенная временем модель, весьма медленная, что не очень хорошо для процессинга каждого кадра видео (~5 fps) |
|
YOLOv4-v5 [10, 15] |
box AP ~55.8 |
Работают в реальном времени, много дискуссий насчет того, какая лучше в плане точности ( v4 или v5), v5 не от darknet , но работает еще быстрее. |
|
DyHead [12] |
box AP 60.6 |
Достаточно новая модель от Microsoft, работает на self-attentions ( swin transformer ). Two-stage – то есть, вероятно, работает не слишком быстро. Из-за новизны есть потенциальные проблемы с дообучением. |
|
Soft Teacher [13] |
Box AP 61.3 |
Новая модель от microsoft , основанная на Swin transformer. |
В качестве лучшей модели была выбрана модель YOLOv 5, она обладает сравнимой точностью детекции с SOTA моделями и при этом впечатляющей скоростью работы.
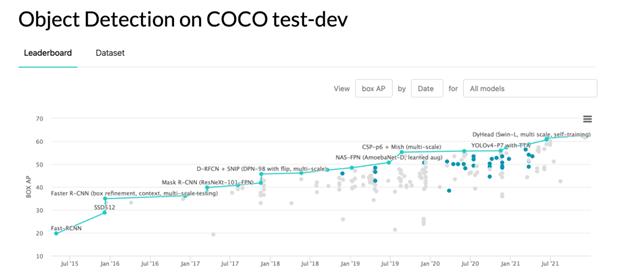
Рисунок 6.1 – Object Detection on COCO test-dev
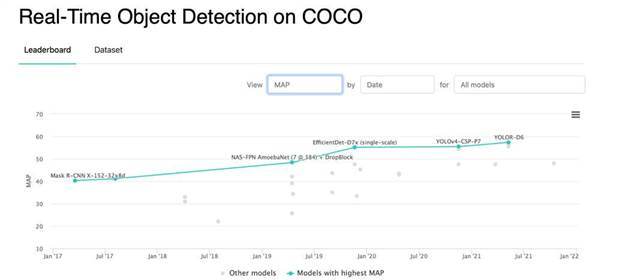
Рисунок 6.2 – Real-Time Object Detection on COCO
Аналогично был проведен анализ литературы для анализа SOTA моделей для распознавания текста по изображению ( Optical character recognition или OCR ). Существует множество решений, использующих архитектуру Transformer [14], но все они работают достаточно медленно, поэтому лучшей моделью была определена модель CRNN.
Полученный набор данных был преобразован для дообучения модели YOLOv 5, само дообучение происходило в течение 10 эпох (после появлялся эффект переобучения). Ниже можно увидеть результат работы дообученной модели детекции.

Рисунок 6.3 – Результат доработанной дообученной модели детекции
Далее, дообученная модель YOLOv 5 была использована, чтобы составить набор данных, содержащий только изображения номеров ( crops ). Аннотации для номеров были взяты из исходного набора. На полученном наборе данных была дообучена модель CRNN . Точность распознавания (доля случаев, когда распознанный номер совпал полностью с действительным) на тестовой выборке составила 96%.
Для изображения выше модель генерирует следующий результат:
[['С861КТ190', 'С931КМ76', 'С441АК76']]
Модели YOLOv 5 (детекции) и CRNN (распознавания) были объединены в компоненту реализуемой библиотеки, выполняющую распознавание номеров автомобилей по видеопотоку и встроены в архитектуру библиотеки. Во время разработки данного модуля компанией ultralytics было опубликовано еще несколько моделей YOLO [30]:
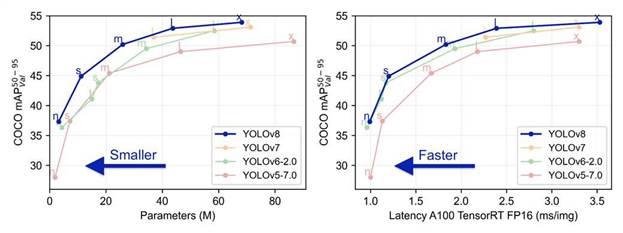
Рисунок 6.4 – Сравнение различных версий модели YOLO по метрике mAP (50-95) на наборе данных COCO .
В алгоритм была встроена и дообучена на номерах автомобилей версия YOLOv8n , обладающая схожей точностью детекции с YOLOv5s , но имеющая меньше параметров и, соответственно, большей скоростью работы.
6.2. Проведение экспериментов и оценка качества разработанных моделей в различных условиях: время дня, внешние шумы (дождь, туман, снег)
С целью обеспечения максимальной стабильности работы алгоритмов в плохих погодных условиях были реализованы методы аугментации изображений и методы проективной геометрии. Аугментация – процесс обогащения набора данных путем генерации их “искаженных” версий. Искажения реализованы нескольких типов:
1) Сдвиги.
2) Повороты.
3) Блики.
4) Дефокус.
5) Сжатия и растяжения.
6) Цветовые (для симуляции ночных фильтров).
Аугментация имеющихся наборов данных позволила получить более устойчивые к различным погодным условиям модели.
Для оценки работы алгоритма в плохих погодных условиях было дополнительно собрано и размечено 357 тестовых изображений (в условиях плохого освещения, заснежности, дождя) изображений автомобилей c помощью сервиса Roboflow . Примеры таких изображений:





Рисунок 6.5 –– Несколько примеров тестовых изображений номеров автомобилей в условиях плохой видимости.
Точность алгоритма на этом наборе данных составила 91±2% (погрешность при кросс валидации из-за относительно небольшого размера выборки). По отдельным категориям различных точность не замерялась, так как для датасет был размечен без меток, означающих какой конкретно тип погодного условия на каждом фото.
6.3 Распознавание номера вагона поезда
Создание обучающих примеров из естественных изображений.
Примеры для обучения из естественных изображений создаются на основе реальных данных. Их создание состоит из следующих этапов:
- Сбор графических данных (фотографирование интересующих объектов, снятие видеопотока с камеры, выделение части изображения на интернет странице).
- Фильтрация — проверка изображений на ряд требований: достаточный уровень освещенности объектов на них, наличие необходимого объекта и т. д.
- Подготовка инструментария для разметки (написание собственного или оптимизация готового).
- Разметка (выделение четырехугольников, необходимых знакомест, интересующих областей изображения).
- Присвоение каждому изображению метки (буква или название объекта на изображении).
В рамках реализации собран набор данных – фото и видео фиксация проезжающих составов в различных условиях. Затем, при помощи инструмента label studio , данные были размечены (отмечены координаты покрывающего прямоугольника для каждого номера). Пример на рисунке 6.6:
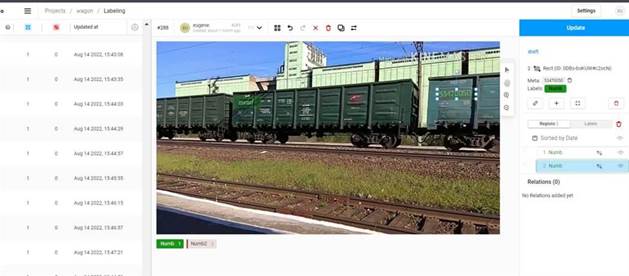
Рисунок 6.6 – Пример разметки данных вагонов
Суммарное количество размеченных кадров – 1151.
Компоненты детекции ( YOLOv 8) и распознавания ( CRNN ) были дообучены на задачу распознавания номеров вагонов на полученном датасете, суммарная точность распознавания на отложенной выборке составила 89% (т.е в 89 процентов случаев модель правильно распознает все символы номера). Полученный результат характеризует хорошую обобщающую способность на сопутствующих задачах и может быть улучшен путем разметки большего количества примеров.
Пример
детекции номерных знаков на вагонах (0 значит принадлежность к классу “номер”)
изображен на рис. 6.7.
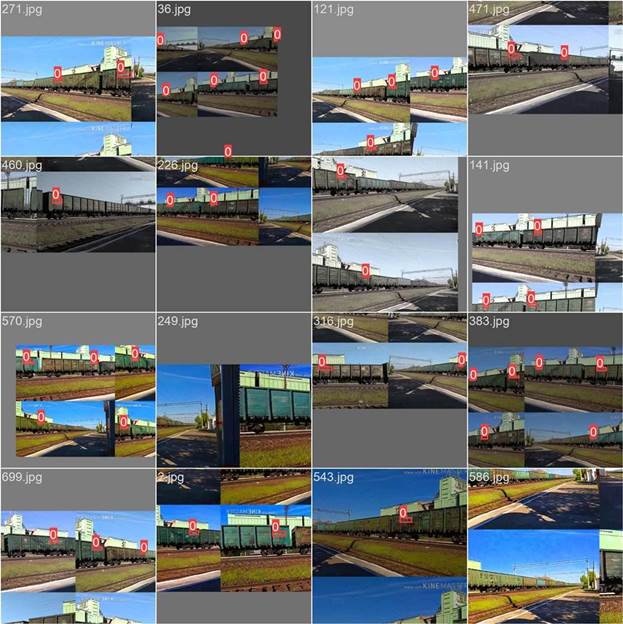
Рисунок 6.7 -Пример детекции номерных знаков на вагонах
6.4 Распознавание QR и штрихкодов
Для распознавания QR и штрихкодов были рассмотрены существующие решения.
Запуск библиотеки OpenCV с алгоритмом zbar показал, что QR -коды, в целом, детектируются лучше, чем штрих-коды такого же размера. Результаты анализа качества считывания представлены на рисунке 6.8 и обсуждаются далее.
Опытным путём было выведено, что усложненные QR -коды начинают детектироваться и корректно считываться, если они занимают ~0.8% кадра, тогда как более простым достаточно ~0.64% кадра. Проценты ниже ~0.74% для усложненных и ~0.57% для простых уже не детектировались.
У штрих-кодов в принципе проблема с детекцией по двум причинам. Во-первых, из-за близко стоящих полосок кадр нередко смазывается. Во-вторых, в отличие от QR -кодов, можно считать штрих-код обрезанно по горизонтали на сколько-нибудь, но при этом данные не потеряются и код считается. Поэтому, например, на некоторых кадрах считывается область, составляющая 0.04% кадра, а иногда детекция 0.74% работает некорректно. Можно отметить, что области выше 0.91% не обрезаются при детекции и распознаются чётко и полностью.
Для эксперимента было взято расстояние, с которого все коды спокойно детектировались (размеры QR - 1.26 см для простого и 1.55 см для сложного). При повороте на угол 43 градуса коды уже не читались. При повороте на угол 40 градусов или меньше всё прочитывалось корректно. Грань, когда перестаёт читаться сложный и начинает читаться простой, поймать не удалось – кажется, нечитабельность наступает примерно одновременно.
Для эксперимента было взято расстояние, с которого все коды спокойно детектировались (размеры штрих-кодов - примерно 0.96% кадра). При повороте на угол 43 градуса коды уже не читались в принципе. При повороте на 40 градусов не все коды прочитывались, а в прочитанных были ошибки детектирования (код читается, но он неверный). Начиная с поворота на угол 33 градуса читалось всё, но как раз стали возникать ошибки детектирования в некоторых случаях. При повороте на 30 градусов или меньше всё считывалось корректно.
Библиотека OpenCV с добавлением библиотеки zbar показали достаточный результат, поэтому решено было адаптировать существующее решение.
|
Не детектится ничего |
Только QR |
Не детектятся (43 градуса) |
Детектятся (40 градусов) |
|
|
|
|
|




Рисунок 6.8 - Результаты анализа качества считывания QR-кодов
6.5 Распознавание номеров произвольной формы, различных шрифтов, маркировок, надписей в условиях различной зашумленности и различных алфавитов
Проведено сравнение работы существующих библиотек для распознавания символов: PaddleOCR , Tesseract , Doctr , EasyOCR на собранном наборе из 1210 фотографий произведенных объектов (металл, пластик, стекло, кирпич, бумага, дерево). Средние значения для расстояния Левенштейна между реальными и распознанными надписями представлены в таблице 6.2 для различных категорий материалов.
Таблица 6.2 - Средние значения для расстояния Левенштейна между реальными и распознанными надписями для различных категорий материалов
|
Матриал\Модель |
PaddleOCR |
Tesseract |
Doctr |
EasyOCR |
|
Металл |
0.057160 |
0.461613 |
0.268681 |
0.181886 |
|
Кирпич |
0.353260 |
0.041227 |
0.335991 |
0.103651 |
|
Стекло |
0.307380 |
0.254498 |
0.270838 |
0.212571 |
|
Пластик |
0.947816 |
0.210128 |
0.147302 |
0.017100 |
|
Бумага |
0.377727 |
0.223795 |
0.270136 |
0.135312 |
|
Дерево |
0.055672 |
0.189703 |
0.188016 |
0.014465 |
|
Разное |
0.124016 |
0.045473 |
0.021668 |
0.031424 |
Результаты показали, что значительную ошибку вызывает неверная детекция положения текста на изображении. Поэтому для детекции текста был использован внешний детектор – модель YOLOv 8 small . С базовыми весами она показывала плохой результат, поэтому для ее дообучения был сгенерирован синтетический набор изображений из 10000 фотографий произвобственных помещений с текстом на них, написанных различными шрифтами русского и английского алфавитов.
|
|
|
|
|
|
|
|
|


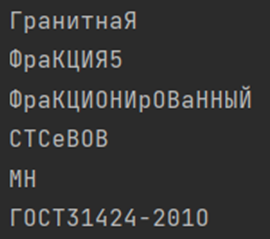

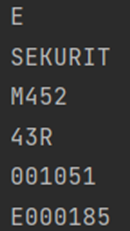
Рисунок 6.9 - Примеры распознавания номеров и текста на объектах.
По результатам тестирования на реальных данных точность алгоритма составила 0.3, что зависит от условий фотографирования номера на объекте. Фотография должна быть чёткой, сделанной при хорошем освещении. Угол наклона текста не должен превышать 20 градусов. Текст должен занимать хотя бы 1.5% кадра для успешного распознания. Текст, написанный вертикально, распознан не будет. Наиболее хорошо распознаются номера, написанные на пластике, стекле, бумаге и картоне.
7. Анализ перемещения объектов (людей, машин и других) в пределах установленной области, а также захват и подсчет объектов
В рамках реализации системы был реализован программный модуль библиотеки, предназначенный для подсчёта легковых автомобилей, грузовиков, велосипедов, мотоциклов, пешеходов или любых других объектов, заданных пользователем.
Основным преимуществом разработанного модуля является возможность построения масштабируемой эффективной промышленной системы в кратчайшие сроки, способной решать широкий спектр задач как на дорогах общественного пользования и в торговых центрах, так и на КПП, цехах и конвейерных лентах заводов. Такое удобство использования обуславливается предусмотренным функционалом для разметки пространства, дообучения моделей детекции семейства, интегрированной предобученной системы детекции и трекинга объектов, а также простотой совместного использования с остальными компонентами библиотеки.
Возможность использования в любой среде, помещении или в уличных условиях, обуславливается возможностью задания областей и потоков с помощью графического интерфейса, работающего следующим образом: пользователю выводится на экран первый кадр видео или любой кадр с камеры наблюдения, после чего он может начертить любое количество линий, предназначенных для подсчёта объектов в потоке, проходящем через нарисованную линию, или же область произвольной формы и заштриховать её для определения находится ли тот или иной обьъект в заданной области или нет. После задания линий, необходимо нажать кнопку сохранить, в результате чего заданные линии будут преобразованы в конфигурационный файл, указываемый при запуске детектора. Интерфейс и результат работы программы задания конфигурации области анализа продемонстрированы ниже, на рисунках 7.1 и 7.2.
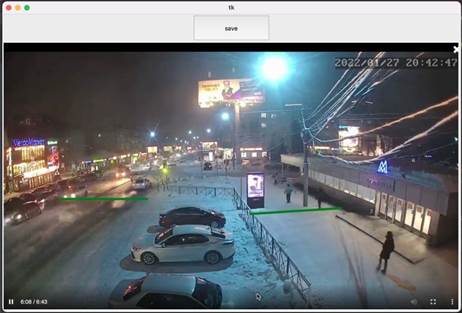
Рисунок 7.1 - Интерфейс задания конфигурации области

Рисунок 7.2 - Пример заданной области
Разработанный функционал может быть использован вместе с любым алгоритмом детекции и трекинга объектов, однако по умолчанию для детекции объектов используется предобученная модель YOLOv 5 [15], а для отслеживания распознанных объектов алгоритм корреляционного мультитрекинга [16]. Использованные решения демонстрируют высокую точность. Необходимость использования трекинга обуславливается возможностью ускорения работы системы путём уменьшения нагрузки на аппаратную часть пользователя, и, тем самым, удешевления процесса разработки более специализированных решений при несущественной потере точности детекции.
В процессе работы системы анализа потоков на экране отображается информация о различных объектах, посчитанных системой, демонстрируются рамки объектов, позволяющие оценить точность детекции и трекинга объектов. Для разных типов объектов рамки отображаются в разных цветах. При пересечении линии объектом происходит его учет в системе, а также может быть подан звуковой или текстовый сигнал в консоли. При необходимости задания более сложного поведения при пересечении объектом линии, разработанная система может быть использована как API.
В ходе первичного тестирования реализованного модуля была продемонстрирована высокая точность и надежность в ночных, дневных и заводских условиях. Процесс работы программы продемонстрирован на рисунках 7.3 и 7.4.

Рисунок 7.3 - Пример определения заезда в заданную область

Рисунок 7.4 - Пример подсчёта ТС и пешеходов в потоках
7.1. Проведение экспериментов и оценка качества разработанных моделей в различных условиях: время дня, внешние шумы (дождь, туман, снег)
Проведена существенная доработка детектора объектов для использования в тяжёлых погодных условиях и в различные времена суток. Была проделана работа по адаптации модели к туману, дождю и снегу, а также к ночному и дневному времени.
Для решения поставленной задачи был собран набор изображений, состоящий из различных видео и фото-фрагментов, снятых в различных погодных условиях и при разном уровне освещенности. Полученный набор данных содержит около 300 фотографий и размечен под 5 классов: машина, пешеход, автобус, велосипед, другой транспорт.
Благодаря адаптации модели к различным условиям освещения, детектор объектов может работать достаточно точно как днём, так и ночью при различных источниках света.
Результаты работы модели в тестовых условиях показали либо незначительное падение точности детекции по сравнению с результатами тестов, проведённых на выборке с ясными погодными условиями, либо результаты, сопоставимые по точности с результатами тестов при ясных погодных условияхи. Результаты тестирования приведены в таблице 7.1.
Таблица 7.1 - Результаты работы модели в тестовых условиях
|
Описание условий |
mAP |
Precision |
Recall |
|
Туман, заснеженные дороги |
0.78834 |
Машины: 0.81348 Люди: 0.79357 Остальные классы: 0.75797 |
Машины: 0.88384 Люди: 0.8203 Остальные классы: 0.83495 |
|
Сумерки, отсутствует искуственное освещение |
0.83389 |
Машины: 0.90943 Люди: 0.78348 Остальные классы: 0.80876 |
Машины: 0.89584 Люди: 0.86074 Остальные классы: 0.90053 |
|
Ночные условия, отсутствует искуственное освещение |
0.814 |
Машины: 0.85391 Люди: 0.77409
|
Машины: 0.87964 Люди: 0.76934
|
|
День, ясные условия, магистраль |
0.84819 |
Машины: 0.98742 Люди: 0.60394 Остальные классы: 0.95321 |
Машины: 0.99834 Люди: 0.97584 Остальные классы: 0.98547 |
|
Закат/ночь, засвет камеры солнцем или фонарями |
0.84651 |
Машины: 0.87253 Люди: 0.82049
|
Машины: 0.92857 Люди: 0.9657
|
|
Закат, ясные условия |
0.86731 |
Машины: 0.97339 Люди: 0.78784 Остальные классы: 0.8407 |
Машины: 0.99342 Люди: 0.94857 Остальные классы: 0.96584 |
|
Снегопад, пасмурная погода, естественное освещение |
0.84713 |
Машины: 0.8736 Люди: 0.81966 Остальные классы: 0.84813 |
Машины: 0.9 Люди: 0.83584 Остальные классы: 0.83874 |
|
Пасмурная погода, отсутствуют осадки |
0.8453 |
Машины: 0.88119 Люди: 0.80941
|
Машины: 0.9445 Люди: 0.87493
|
|
Мокрая камера |
0.92258 |
Машины: 0.986 Люди: 0.85916
|
Машины: 0.99583 Люди: 0.9019
|
В таблице 7.1 представлены средняя точность и точность по отдельным классам, а также полнота. В силу специфики используемого набора данных, велосипеды, автобусы и прочие транпортные средства встречаются либо заметно реже по сравнению с людьми и машинами, либо их доля слишком мала для оценки приведённых параметров. Этим обуславливается выделение описанных классов в пункт “остальные классы”. Полученные результаты демонстрируют, что ночные и туманные условия, а также засветы заметно снижают полноту распознавания машин и людей.
7.2. Тестирование, оптимизация скорости работы алгоритмов
Для ускорения работы модели детекции в рамках данного системы были предприняты определенные меры. В частности, было выполнено переписывание нейронной сети YOLOv 5 под внутреннюю структуру проекта. В целях уменьшения размеров библиотеки было решено добавить поддержку двух основных размеров нейронной сети: 213 и 367 слоёв. Это позволило значительно увеличить эффективность работы алгоритма и избежать накладных расходов, связанных с избыточным преобразованием изображений в различные форматы.
Кроме этого, был проведен рефакторинг кода, который позволил упростить его структуру и устранить такие проблемы, как дублирование кода, неэффективные алгоритмы, избыточный код и т.д. В результате удалось значительно ускорить работу алгоритма и улучшить качество детекции объектов на изображениях. Описанные выше меры позволили достичь незначительного ускорения работы алгоритмов и существенного повышения качества программного кода, не потеряв при этом достаточно высокой точности.
Для тестирования работы моделей детекции была проведена серия экспериментов на наборе данных, содержащем изображения с различными объектами. Был произведен анализ точности и времени работы алгоритмов на разных конфигурациях нейронной сети, что позволило выбрать наилучшую версию для использования в проекте. В процессе тестирования было обнаружено, что наибольшее влияние на точность работы алгоритмов детекции оказывает выбор метода предобработки изображений. Был предложен оптимизированный подход, который позволил достичь наибольшей точности при минимальных временных затратах.
Для улучшения производительности была внедрена технология GPU-acceleration , которая существенно ускорила работу алгоритмов на оборудовании с высокой производительностью GPU.
Для определения скорости различных объектов были проведены эксперименты на наборе видео, содержащем движущиеся объекты разных типов и размеров. Благодаря этим экспериментам удалось определить скорость движения объектов и скорость работы алгоритмов на разных типах задач. Также была разработана методика тестирования скорости работы алгоритмов детекции на различных типах аппаратного обеспечения.
8. Разработка алгоритмов определения размеров (распределений по размерам) объектов различной природы (руда на конвейере, люди в очереди, транспортный средства в потоке и т.д.)
Разработанный алгоритм позволяет классифицировать транспортные средства по типу кузова и, таким образом, определять их размеры. Это может быть необходимо при анализе поставок на заводах, фильтрации т/с, которые могут угрожать безопасности персонала или при проектировке контрольно-пропускных пунктов, однако использование этого модуля не ограничивается приведёнными ситуациями. Процесс работы модуля продемонстрирован на рисунке 8.1. Точность классификации при IoU 0.5 составила 0,962.


Рисунок 8.1 - Пример определения размеров кузова
8.1 Гранулометрия
Гранулометрический анализ – распределение камней руды по крупности, характеризующееся процентным выходом от массы или количества кусков руды. Гранулометрический состав – важный физический показатель качества руды. Состав руды влияет на дальнейшее дробление и измельчение, так как при преобладании крупных камней мельницу необходимо убыстрять, при преобладании мелких – замедлять для повышения эффективности работы агрегата. В общем случае, гранулометрия - процесс оценки размеров объектов.
Стандартом для оценки распределения частиц является ситовой анализ, применяемый к забору пробы (1 м3) руды из контейнера и дальнейшего просеивания сквозь сита разной размерности. Точность данного метода низкая, так как он работает на допущении, что распределение камней в пробе и контейнере совпадают. Дорогостоящими методами, требующими дополнительного оборудования, являются инфракрасная трёхмерная съемка, трёхмерное лазерное сканирование, флуоресцентный рентнегорадиометрический анализ. Существующие промышленные решения являются пропиетарными. Продукты для гранулометрического анализа конфигурируются для конкретного производства в связи с отличающимися условиями. Чаще всего предприятия предлагается готовый аппаратно-программный комплекс, сконфигурированный под конкретное предприятие, однако, это не всегда допустимо.
Автоматизация построения распределения камней по размеру может быть реализована с помощью применения компьютерного зрения к существующим данным, которым является видео с конвейера [9].
Осуществление гранулометрического анализа происходит следующим образом:
1. получение изображения с камеры;
2. предобработка изображения;
3. определение камней на конвейере;
4. дополнительный шаг: отслеживание камней;
5. построение распределения.
Цель предобработки изображений – подготовить исходные данные изображения для извлечения необходимой нам информации, повысить вероятность определения именно тех объектов, которые нам необходимы. Исходные кадры с конвейера требуют предобработки, так как имеют низкую яркость, и объекты сложно различимы. Дополнительную сложность вносит однородность объектов. Задача предобработки - выделить объекты для дальнейшего анализа.
Предварительная обработка кадра (рис. 8.1) включает в себя:
1. Кадрирование изображения для выделения ленты конвейера. Кадрирование является наиболее простым шагом предобработки и позволяет не выявить лишних деталей.
2. Уменьшение шума путём применения размытия по Гауссу. Фильтр Гаусса часто применяется для сглаживания изображения, удаления шумов и улучшения структуры изображения.
3. Эквализация гистограммы. Данная операция позволяет повысить яркость и контраст изображения. Цель эквализации - преобразование гистограммы таким образом, чтобы она соответствовала нормальному закону распределения.

Рисунок 8.2 - Процесс предобработки изображения
Основная проблема исследования – определение камней на конвейере. Для решения этой задачи необходимо произвести сегментацию изображения, выделив пиксели, принадлежащие камням или фону (к фону так же относятся элементы конвейера). Существуют два ключевых подхода к сегментации: на основе выделения границ и на основе метода выращивания регионов, а также смешанный подход. Простые методы не могут полностью решить задачу детектирования камней на плоскости, однако, их использование эффективно в качестве этапов сегментации. Метод водораздела относится к методам выращивания регионов и является одним из самых популярных и эффективных методов сегментации.
Суть метода водораздела заключается в обнаружении маркеров [6], которые будут являться точками локального минимума, точек, находящихся на возвышенности и точек, находящихся на склоне, с которых вода разных цветов будет сливаться к центру водоёма.
Алгоритм работы метода водораздела следующие:
a . В местах локального минимума образуются отверстия, через которые вода начинает заполнять поверхность.
b . Если вода с двух сторон возвышенности готова слиться в один бассейн, то необходимо установит перегородку между бассейнами.
c . Когда вода заполнит всё изображение, то алгоритм можно остановить.
Использование водораздела часто приводит к сильной сегментации, поэтому чаще всего используют водораздел на основе маркеров. Маркер являет собой точку локального минимума, на основе которого будет выбран бассейн. Маркеры возможно расставлять как вручную, так и автоматически.

Рисунок 8.3 – Процесс расстановки маркеров и вычисление маски
Оценка точности определения камней на конвейере была произведена с помощью матрицы ошибок (таблица 1), в которой сравнивались маски сегментации, построенные вручную и с помощью нейронной сетью. Если пересечение между реальной и сегментированной маской превышало 70%, то сегментация признается истинно положительной ( TP , True positive ), иначе результат признавался ложноположительным ( FP , Falsepositive ). Истинно отрицательный результат ( TN , true negative ) не применим к данной задаче, и на всех изображениях равен нулю.
Выделенный объект классифицировался как ложноотрицательный результат ( FN , False negative ), если камень был определён как фон, т.е. не определён вообще. Вычисление происходило на основе 10 случайно выбранных изображений конвейера, прошедших предобработку (размер 256х256 пикселей, 8-бит, градации серого). На основе этих данных были вычислены следующие метрики: точность (1) и полнота (2). Точность позволяет определить долю верно определённых объектов относительно всех объектов.
Таблица 8.1 – Матрица ошибок и метрики метода водораздела
|
|
Реальное положение |
Точность |
Полнота |
|
|
Вычисленное |
Камни |
Фон |
60% |
84% |
|
Камни |
TP = 736 |
FP = 490 |
||
|
Фон |
FN = 134 |
TN = 0 |
||
Из таблицы 8.1, построенной на базе выборки из 10 изображений, видно, что метод водораздела не обеспечивает высокую точность, но значение полноты, превышающее значение точности, позволяет сделать вывод, что это происходит вследствие выделения большого количества лишних ( false positive ) объектов, таких как детали конвейера. Таким образом, метод водораздела не подходит для определения камней на конвейере, однако его можно использовать как базовый метод для обучения нейросети.
В качестве нейронной сети выбрана сеть U-Net [7], которая считается одной из стандартных архитектур свёрточных нейронных сетей, используемых для задач сегментации изображений. Особенность данной нейронной сети в том, что она позволяет сегментировать область по классу, т.е., создать маску, позволяющую разделить изображение на несколько классов [8].
Изображения обучающей выборки, полученные с помощью метода водораздела, были модифицированы с использованием графического редактора. Убраны ошибочно выделенные объекты, такие как детали конвейера, убраны распознанные как крупные камни области песка (ошибка разделения мелких частиц), выделены границы для нескольких камней, распознанных как один, или убраны для камней, распознанных как несколько.

Рисунок 8.4 – Сравнение результатов сегментации методами водораздела и с помощью нейронной сети
Экспериментальным образом было подобрано время обучение в течение 5 эпох и 2000 шагов в каждой эпохе. Полученное значение функции потерь 0.15, полученная точность - 98.5 обучения. Проверим результат работы алгоритма на тестовой выборке, не пересекающейся с обучающей. Согласно таблице 2, достигнута точность около 95%, что значительно превышает метод водораздела. Относительно классических методов компьютерного зрения, нейронная сеть обучена таким образом, что не выделяет области мелких камней как один большой камень (ошибка разграничения частиц), что является плюсом (рис.3). Однако, при использовании этого метода, как и все методов, использующие двумерные изображения, сложно избежать ошибку профиля, то есть неправильного определения реального размера камни из-за тени.
Таблица 8.2 – Матрица ошибок и метрики нейронной сети
|
|
Реальное положение |
Точность |
Полнота |
|
|
Вычисленное |
Камни |
Фон |
94,4% |
94,9% |
|
Камни |
TP = 947 |
FP = 56 |
||
|
Фон |
FN = 23 |
TN = 0 |
||
Временные затраты на вычисление маски одного изображения (аппаратное обеспечение CPU XeonProcessors @2.3 Ghz, GPU Tesla K 80 12 GB VRAM , RAM 13 GB ) можно разделить на следующие: метод водораздела – 0,04 с, нейронная сеть – 0,09 с. Согласно построенной матрице ошибок и вычисленным метрикам по 10 изображениям (таблицы 7.1, 7.2) можно сделать вывод, что нейронная сеть Unet обеспечивает точность детектирования, превосходящую метод водораздела в 1,57 раза, а время обработки одного изображения продолжительностью 0,09 с позволяет работать в реальном времени.
Финальным этапом является построение распределения по результатам детектирования камней на ленте конвейера мы можем построить диаметр Ферета (опоясывающая рамка, перпендикулярная осям X и Y) для каждого из камней.
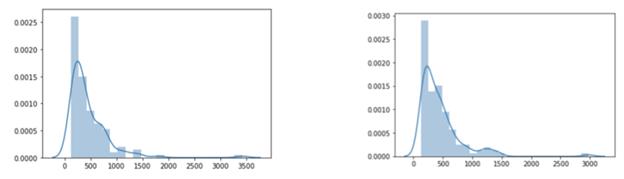
Рисунок 8.5 – Построенное распределение
На основе этих данных мы можем построить гистограмму (рис.5), которая будет показывать распределение камней по размеру на данном участке конвейера. В качестве размера берётся площадь полученного прямоугольника.
На построенном примере распределения мы можем видеть преобладание камней небольшой площади. На основе накопленных данных распределения определяются пороговые значения размеров камней, по которым можно определять крупность для управления мельницей.
Получен набор методов для автоматизации гранулометрического анализа, в том числе для детектирования камней на конвейере и определения частоты детектирования.
Наилучший результат детектирования показало использование нейронной сети Unet , предназначенной для семантической сегментации изображений. Нейронная сеть была обучена на выборке, созданной с помощью метода водораздела, скорректированного вручную.
8.2 Разработка и имплементация алгоритмов классификации транспортных средств (категории объекта (тип транспортного средства, металла, дерева, и других материалов)
Классификация транспортных средств подробно рассмотрена в разделе 7, здесь же опишем определение типа материала. На данном этапе разработанный алгоритм позволяет с точностью до 0.83 определять один из трёх типов материала: дерево, сталь, бетон. Важными требованиями к работоспособности системы являются: независимость от фона, освещённости, расположения и формы элементов и поверхностей.
В качестве детектора используется встроенная в библиотеку модель YOLOv 5, обученная на данных собранных и преобразованных специально для обучения модели. Одним из основных преимуществ данной архитектуры является высокая скорость работы при высокой точности. Данное свойство системы будет являться критически важным в аналитических системах реального времени.
Благодаря тому, что разрабатываемый модуль библиотеки не заточен под конкретную задачу, система является гибкой и может иметь множество различных применений. Так, разработанный алгоритм может быть применён в различных областях: обеспечение безопасности на стройках и в цехах, системы планировки ремонта и прочее.
Для обучения модели был сгенерирован и автоматически размечен синтетический набор данных. Полученный набор данных состоит из фотографий улиц, рабочих помещений и строек, на которые добавлено от 1 до 10 изображений поверхности одного из распознаваемых материалов. Примеры изображений из сгенерированного набора приведены на рисунках 8.6 и 8.7. Пример работы алгоритма продемонстрирован на рисунках 8.8.а и 8.9.

Рисунок 8.6 - Примеры изображений из сгенерированного набора

Рисунок 8.7 - Примеры изображений из сгенерированного набора

Рисунок 8.8 - Пример работы алгоритма

Рисунок 8.9 - Пример работы алгоритма
9. Разработка компонента системы для определения положения объектов в пространстве
Задача определение положения объектов в пространстве заключается в детекции необходимого объекта объекта и построении его координат в пространстве относительно выбранного начала координат.
В рамках библиотеки разработан компонент для определения положения объектов в пространстве в двух вариантах:
1. При наличии информации о размере одного из объектов с использованием одной камеры.
2. При отсутствии информации о размере объектов с использованием стереокамеры.
При наличии информации о размере одно из объектов возможно использование только одной камеры для, так как это этой информации достаточно для того, чтобы рассчитать расстояние до объекта и его смещение относительно начала координат (в случае, если они находятся на одной расстоянии от камеры). Если объекты находятся на разном расстоянии, тогда каждая камера может осуществлять расчёт координат по двум осям.
Для повышения точности расчёта координат необходимо выставлять камеры перпендикулярно объектам, координаты которых необходимо узнать.
Расстояние до объекта в данном случае считается по формуле:
![]()
где (F )-фокусное расстояние объектива, М - линейный масштаб, рассчитываемое по формуле
![]()
где L о - размер объекта, L к - линейному размеру его изображения в кадре.
При отсутствии информации о размере объектов используется стереокамера, осуществляющая расчёт карты глубины. Тогда мы фиксируем точку отсчёта и рассчитываем расстояния до точки по формулам:
dx = x1 - x2
dy = y1 - y2
dx = dx * 53 / 28
dy = dy * 45 / 28
z1 = 1017./np.mean(bbox_w)
z2 = 1017./np.mean(bbox_h)
dz = z1-z2
dist = (dx ** 2 + dy ** 2 + dz ** 2) ** 0.5
Где константы - baseline перевода размеров.
10. Разработка моделей определения скорости объектов
Разработан и реализован модуль детекции различных объектов и определения скорости их движения, включающий в себя в том числе графический интерфейс системы. Результаты работы модуля имеют большую значимость для многих областей, от сферы безопасности до управления транспортной инфраструктурой.
Модуль использует несколько различных алгоритмов компьютерного зрения для подсчёта скорости объекта: нейронную сеть yolov 5, состоящую из 367 слоёв и содержащую свыше 46 миллионов параметров, трекер объектов SORT для отслеживания обнаруженных объектов и сравнения положений их центроидов, а также алгоритм расчёта скорости, использующий данные о положениях центроидов, заранее известные размеры объектов (ширина или длина кузова), также частоту кадров, размер кадра и свободный параметр, необходимый для более точной калибровки системы.
Ниже приведена формула, по которой присходит расчёт скорости:
![]()
![]()
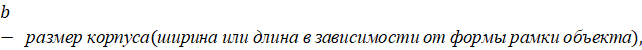
![]()
![]()
Результаты тестов показали, что модуль способен распознавать различные объекты, такие как автомобили, пешеходы, велосипедисты и мотоциклисты, а также определять скорость их движения с высокой точностью. Среднее отклонение рассчитанной скорости составляет менее 5 км/ч. Это позволяет использовать модуль в различных областях, включая сферу безопасности на дорогах и транспортное управление.
Модуль имеет высокую скорость обработки, что делает его идеальным для использования в реальном времени. Его производительность была проверена и подтверждена на различных тестовых наборах данных. Так скорость работы детектора в среднем составляет 0.037 с., а общее время работы алгоритма составляет менее 0.07 с.
В целом, модуль детекции различных объектов и определения скорости их движения - это важный инструмент, который может быть использован в различных областях. Благодаря проделанной работе его производительность и точность превосходят многие существующие аналоги.
На рисунке 10.1 продемонстрирован результат работы системы определения скоростей объектов.
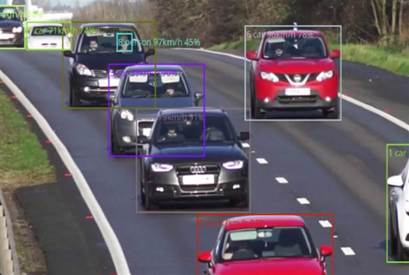
Рисунок 10.1 - Результат работы системы определения скоростей объектов
11. Внедрение в алгоритмы компьютерного зрения инструментов и методов проективной геометрии.
Были реализованы методы аугментации изображений методами проективной геометрии. Аугментация – процесс обогащения набора данных путем генерации их “искаженных” версий. Искажения реализованы нескольких типов:
1) Сдвиги.
2) Повороты.
3) Блики.
4) Дефокус.
5) Сжатия и растяжения.
6) Цветовые (для симуляции ночных фильтров).


Рисунок 11.1 – пример аугментации поворотом


Рисунок 11.2 – поворот, блики и сатурация.

Рисунок 11.3 – поворот, сдвиг, размытие и pixel noise .
Другие методы проективной геометрии, реализованные для будущих задач:
1) Представление точек в 2 D и 3D с помощью трехмерных и четырехмерных векторов соответственно.
2) Введение точек на бесконечности, которые могут быть обработаны как обычные точки.
3) Описание проективных преобразований с использованием матриц, включая представление трансляций и общих аффинных преобразований.
4) Расчет точек пересечения, плоскостей или линий через заданные точки с использованием простых векторных произведений или тензорных диаграмм.
5) Использование особых комплексных точек на бесконечности и кросс-соотношений для расчета углов и построения перпендикулярных геометрических структур.
6) Представление наборов точек и линий с помощью тензоров, а также расчет связующих линий и пересечений с использованием быстрого умножения матриц.
12. Разработка компонента системы для автоматической оценки количества и качества данных, требуемых для эффективной работы системы.
Обнаружение объектов на изображении — актуальная задача, которая
находит применение во многих областях как промышленной, так и исследовательской деятельности и решается в разрабатываемой библиотеке. Для этого используется выложенная в открытый доступ модель, предобученная на распространенном наборе данных, например, ImageNet , которая затем дообучается на пользовательском наборе данных, специфичном для решения его задачи. Одним из важных параметров дообучения является размер обучающей выборки. Согласно законам масштабирования нейросетей, чем он больше, тем выше качество работы модели. Однако сбор и разметка набора данных — это, зачастую, затратный процесс, поэтому предпочтительным является наименьший размер набора данных, обеспечивающий желаемое качество работы модели. Целью данной части исследования является реализация метода предсказания размера набора данных, необходимого для дообучения сети и достижения ей целевого качества в задаче детекции объектов на изображениях при условии данной предобученной сети. Важно отметить, что детектирование будет производиться в производственных условиях, где сбор данных затруднен.
Существуют законы масштабирования нейросетей (англ. neural scaling laws ) [30] позволяют экстраполировать зависимость функции потерь для данной модели в зависимости от размера обучающей выборки, благодаря чему может использоваться для ответа на вопрос: ”Какой объем данных необходим для обучения данной модели для достижения желаемого качества работы?”.
Рассмотрим схему предлагаемого подхода. Пусть собраны и размечены n типовых изображений из обучающей выборки. Для каждого из этих изображений, объект отделяется от фона. Затем, для полученных изображений подсчитываются признаки из заранее выбранного набора. Полученные вектора признаков вместе с желаемым mAP затем подаются на вход модели, которая возвращает предсказанный размер обучающей выборки (рис. 12.1).
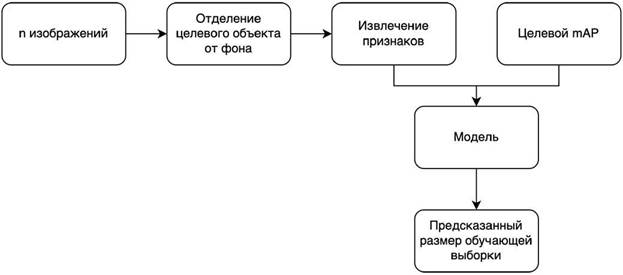
Рисунок 12.1 -Схема предлагаемого подхода
12.1. Выделение признаков
Выделение признаков (англ. Feature extraction ) позволяет для заданного набора данных получить информативное неизбыточное представление, называемое признаками, которое далее может быть использовано в качестве входных данных для алгоритма машинного обучения. Выделение признаков изображений часто используется в таких областях компьютерного зрения, как детекция объектов и поиск изображений [22]. Признаки изображений могут быть созданы вручную или извлечены с помощью методов машинного обучения.
Широко распространена следующая классификация созданных вручную признаков [22]:
— признаки общего назначения:
– признаки цвета (англ. color features);
– признаки текстуры (англ. texture features);
– признаки формы (англ. shape features);
— признаки, специфичные для области применения (например, признаки лица, отпечатка пальца и т.д.).
Признаки цвета считаются одними из наиболее важных и интуитивно понятных низкоуровневых признаков. Значения признаков из данной группы сильно зависят от выбранного цветового пространоства (например, RGB , HMMD , HSV и LUV ). Данная группа признаков устойчиова к масштабированию, повороту и сдвигу изображений [22], [23], [24].
Признаки текстуры – полезная характеристика для многих изображений. Считается, что человеческий мозг опирается на текстуру визуального объекта для его распознавания и интерпретации. В отличие от признаков цвета, которые используют информацию отдельных пикселей, признаки текстуры рассчитываются на основе групп из нескольких пикселей. Было предложено множество методов для извлечения признаков текстуры изображений, однако все из них можно разделить на две группы: пространственные (англ. spatial texture feature extraction methods ) и спектральные (англ. spectral texture feature extraction methods ). Первые опираются на статистики, подсчитанные на основе пикселей оригинального изображения, в то время как вторые сперва отображают изображение в частотное пространство, а затем проводят нужные вычисления. Спектральные признаки отличаются большей устойчивостью к преобразованиям изображения, однако зачастую их сложнее интерпетировать [23].
Признаки формы важны для обнаружения и распознавания объектов реального мира. Они наиболее важны при сравнении нескольких объектов и определения их принадлежности к некторому классу. Признаки формы могут быть извлечены на основании контура объекта (англ. contour based shape feature extraction methods ) или всего участка изображения, занимаемого объектом (англ. region based shape feature extraction methods ). Данная группа признаков также позволяет характеризовать пространственное отношение между объектами на изображении [22], [23].
В данной части библиотеки для характеристики изображения мы выбрали гистограмму цветов (англ. color histogram ) [25], локальные бинарные шаблоны (англ. local binary patterns ) [26] и гистограмму направленных градиентов (англ. histogram of oriented gradients ) [27] в качестве признаков цвета, текстуры и формы соответственно.
Составленные человеком признаки, такие, как описанные выше дескрипторы цвета, формы и текстуры, описывают изображение в легко интерпретируемой человеком форме. Кроме того, они зачастую отражают информацию, необходимую для решения конкретной узконаправленной задачи. Так, например, при подсчете гистограммы направленных градиентов и локальных бинарных шаблонов, отбрасывается информация о цвете изображения, которая может быть потенциально важна при решении некоторых задач [28].
Альтернативным подходом является использование нейронных сетей. Скрытые слои сверточной нейронной сети содержат представление изображения, актуальное для задачи, решаемой сетью. Начальные слои сети содержат более общее представление изображения, которое может быть переиспользовано для решения различных задач. Мы предлагаем использовать признаки, извлеченные из скрытого слоя нейронной сети. Для этого мы предлагаем использовать InceptionV 3 [29]. Архитектура данной сети приведена на рис. 12.2. Для извлечения признаков была использована чать сети, помеченная символом A.
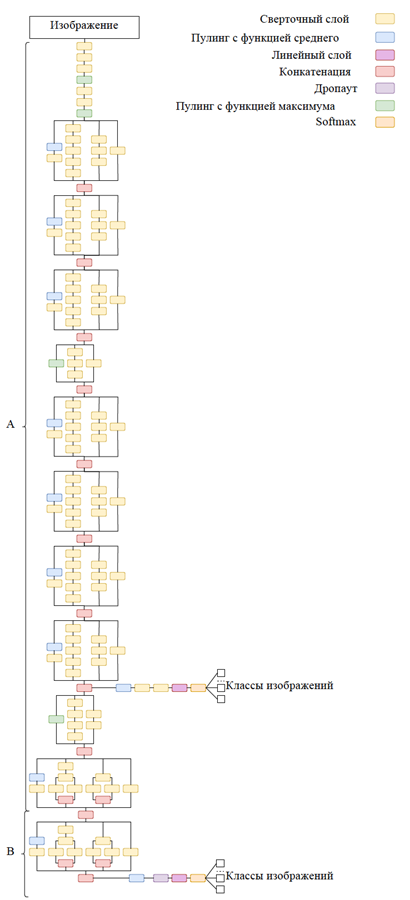
Рисунок 12.2 - Архитектура сети InceptionV3
12.2. Архитектура сети для предсказания размера набора данных
Рассматриваем два подхода к предсказанию размера набора данных для дообучения модели детекции. Первый из них использует признаки, извлеченные вручную, а второй – признаки, извлеченные из промежуточного слоя нейронной сети. Решение использовать разные нейронные сети для разных наборов признаков изображений было мотивировано как разницей в их размере (извлеченные вручную признаки заметно компактнее признаков, извлеченных из промежуточного слоя такой сверточной нейронной сети, как InceptionV 3), так и их различной природой.
12.2.1. Архитектура сети для признаков, извлеченных вручную
В рамках первого подхода мы предлагаем использовать извчеленные вручную признаки, а именно гистограмму цветов, локальные бинарные паттерны и гистограмму направленных градиентов. Данный набор признаков позволяет описать изображение с разных точек зрения (цвета, текстуры и формы), интуитивно понятных для человека. Однако эта группа признаков не отражает, насколько различны изображения из рассматриваемого набора данных, что может повлиять на качество работы модели детекции. Для решения этой проблемы мы предлагаем добавить группу признаков, содержащую среднее попарное расстояние между различными признаками изображений. В качестве признаков, мы выбрали следующие:
— гистограмма цветов;
— локальные бинарные паттерны;
— гистограмма направленных градиентов;
— признаки, извлеченные из премежуточного слоя сверточной нейронной сети VGG 16 [31];
— признаки, извлеченные из премежуточного слоя сверточной нейронной сети ResNet 18 [9].
Указанные выше признаки вместе с желаемым mAP мы предлагаем объединить в один вектор и подавать на вход нейронной сети, архитектура которой представлена на рис. 3.
Предложенная сеть имеет входной слой длины n , равной длине вектора признаков. Скрытые слои сети организованы в пятнадцать блоков. Каждый блок содержит линейный слой с дополнительной связью (англ. skip connection ), обеспечивающей переиспользование признаков. Выход седьмого блока подается на дополнительный выходной слой. Использование дополнительного выходного слоя мотивировано стремлением повысить точность признаков на ранних слоях сети, а тажке борьбой с затухающим градиентом. Как основной, так и дополнительный выходные слои имеют длину один. Оба выходных слоя возвращают оценку размера обучающей выборки.
В качестве функции активации была использована ReLU . Перев каждым
скрытым линейным слоем используется дропаут (англ. dropout ) с вероятностью 0,25.
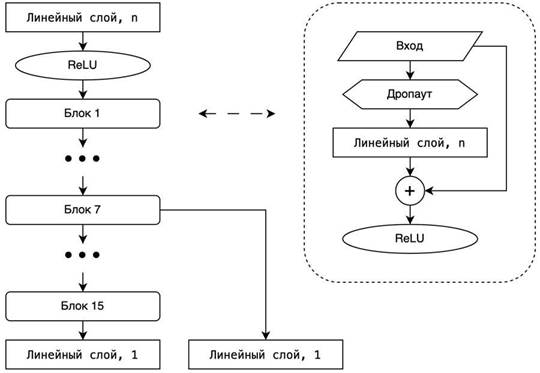
Рисунок 12.3 - Архитектура сети для признаков, извлеченных вручную
12.2.2. Архитектура сети для признаков, извлеченных с помощью неронной сети
Для решения задачи предсказания размера обучающей выборки для достижения заданного качества работы алгоритма детекции с помощью признаков, извлеченных с помощью части A сети InceptionV 3 мы модифицировали часть B этой сети так, чтобы она могла принимать на вход целевой mAP . Для этого заданный mAP подается на вход линейного слоя с выходом размера 64. Полученный выход затем приводится к форме ( b ; 1; 8; 8), где b – размер используемого батча и конкатенируется с векторами признаков n изображений, подсчитанным с помощью части A сети InceptionV 3. Результирующий вектор затем подается на вход части B сети InceptionV 3, отличающейся от оригинальной отсутсвием Softmax -слоя на выходе. Полученная архитектура приведена на рисунке ниже. Как результат, полученый алгоритм можно рассматривать как дообучение сети InceptionV 3 при замороженной части A.
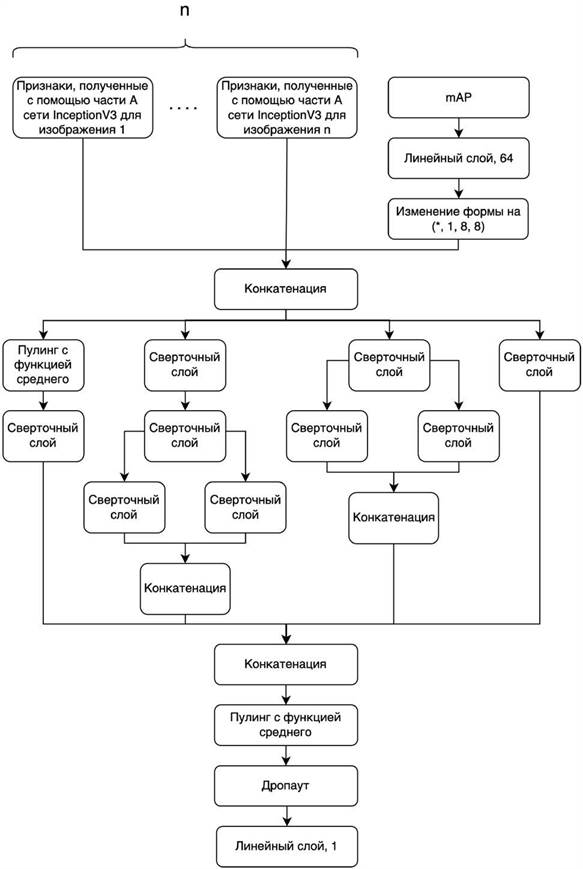
Рисунок 12.4 - Архитектура модифицированной части сети InceptionV3
12.3. Подготовка набора данных для обучения модели
В процессе работы возникла потребность в создании набора данных, содержащего информацию, необходимую для обучения алгоритмов предсказания размера набора данных. Данный набор данных должнен был содержать информацию о том, какого качества работы сети q возможно достичь при дообучении целевого алгоритма детекции A на обучающей выборке T ( s ) размера s . Кроме того, набор данных должен содержать информацию о том, какие изображения входили в обучающую выборку T ( s ) . Очевидно, что достигнутое для обучающей выборки T ( s ) качество обнаружения объектов q зависит от использованного алгоритма детекции A . Соответственно, искомый набор данных должен быть собран отдельно для каждого алгоритма детекции A , для которого необходимо оценить размер обучающей выборки.
Чтобы при обучении отразить максимально возможный спектр задач предсказания размера обучающей выборки, было выбрано 168 наборов данных. Данные наборы содержат различные группы классов объектов детекции, таких как
— дефекты производства;
— животные и насекомые;
— маски и головные уборы;
— различные типы мусора;
— снимки, полученные в результате магнитно-резонансной томографии и
с помощью микроскопа;
— игральные карты и прочие объекты.
Важно отметить, что выбранные наборы данных имеют различные размеры, варьирующиеся от 23-х до трех тысяч изображений. Каждый из выбранных наборов данных был разделен на тренировочное, валидационное и тестовое множество. Тренировочное множество для всех классов составляет приблизительно 80% от размера всего набора данных. Для каждого набора данных T был зафиксирован набор размеров обучающей выборки ST = { s 1 ( T ) , s 2 ( T ), …, sm ( T ) } , для которых должно проводиться дообучение. Размер наборов m для всех классов приблизительно одинаков, чтобы обеспечить равный вклад различных классов в целевой набор данных. Минимальный размер набора размеров обучеющей выборки S равен 17, максимальный – 24, средний размер набора S равен 22 изображениям. При составлении набора размеров больший приоритет был отдан небольшим размерам обучающей выборки.
Для каждого размера обучающей выборки si ( T ) было зафиксировано подмножество обучающей выборки T ( si ( T ) ) , на котором затем был дообучен алгоритм обнаружения объектов A . Затем для алгоритма A на тестовом множестве были подсчитаны метрики IoU и mAP . Полученные метрики затем заносились в целевой датасет вместе с min(si ( T ) , 20) изображениями из обучающей выборки T ( si ( T ) ) .
В результате были получены два набора данных, содержащие порядка 58 тысяч пар типа изображение – размер.
12.4. Предсказание размера набора данных
Сравнение моделей, обученных на признаках, составленных вручную, для разного числа изображений, по которым проводилось усреднение, приведено в табл. 12.1. Табл. 12.2 содержит сравнение моделей, полученных с помощью дообучения сети InceptionV 3 для различного числа изображений, поданного на вход.
Таблица 12.1 - Сравнение моделей, обученных на признаках, составленных вручную, для различного числа изображений, по которым проводилось усреднение внутриклассового расстояния между признаками изображений
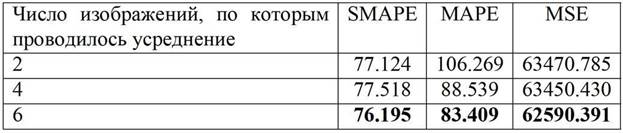
Таблица 12.2 - Сравнение моделей, полученных с помощью дообучения сети
InceptionV 3 для различного числа изображений, поданных на вход
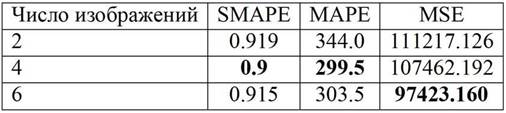
На рисунке 12.5 показано сравнение разработанной модели с законом масштабирования нейросетей.
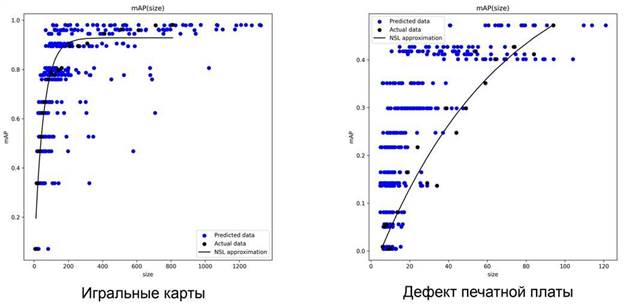
Рисунок 12.5 - Сравнение с законом масштабирования нейросетей (полносвязная сеть, 6 изображений)
Итого, разработан алгоритм предсказания размера обучающей выборки для дообучения сети детекции с желаемой точностью, для чего был выбран набор признаков изображений и предложены архитектуры нейронных сетей. Было проведено сравнение качества предсказаний, как между предложенными алгоритмами, так и с законами масштабирования нейросетей. Предложенный подход позволяет достичь хорошего качества предсказаний даже при небольшом числе поданных на вход изображений.
13. Разработка графического интерфейса пользователя
13.1. Интерфейс калибрации для стереозрения
Разработан графический интерфейс на основе openCV для совместной калибровки двух камер с помощью шахматной доски. На вход подается два видео-файла (или доступ к двум видеокамерам). Необходимо вручную выбрать начало видео для калибровки (начиная с которого на кадрах присутствует шахматная доска) в помощью нажатия клавиша “ s ”. По окончанию калибровки необходимо нажать клавишу “ q ”. Калибровочная информация будет сохранения в текстовый файл conf.txt

Рис. 13.1 - пример графического интерфейса совместной калибрации
13.2. Интерфейс для ручного выбора объектов для отслеживания
Разработан графический интерфейс с помощью OpenCV для выбора объектов для отслеживания (если детекция не осуществляется автоматически). На вход подается видеофайл и количество объектов, которые будут выделены. Можно пропустить видео до момента появления этих объектов, остановка видео производится нажатием кнопки s . Далее необходимо выделить каждый объект на экране с помощью нажатия клавиши “ n ”, выделения объекта в регион интереса с помощью мыши и подтверждения с помощью нажатия клавиши Enter .
|
|
|
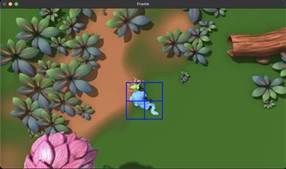
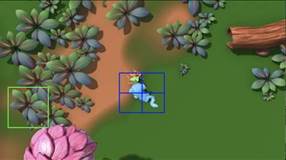
Рисунок 13.2 - Пример выбора объектов с помощью графического интерфейса
13.3. Интерфейс для оценки размера тренировочного набора изображений
Было реализован компонент библиотеки с графическим интерфейсом, которое позволяет пользователю выбрать папки, содержащие изображения и подготовленные для них лейблы, а также целевой mAP (рис. 13.3).
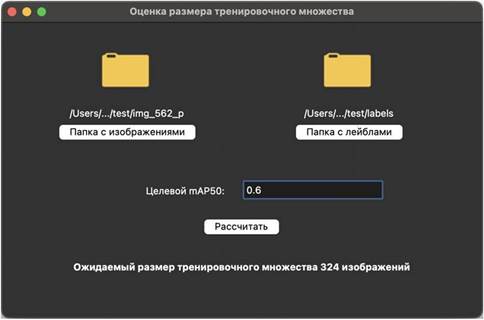
Рисунок 13.3 - Графический интерфейс пользователя
14. Разработка методов автоматического машинного обучения, релевантных для поставленных задач
На производстве возникает много задач компьютерного зрения, например, сортировка продукции по качеству, контроль за перемещениями оборудования и сотрудников. Постоянно возникают частично новые задачи (например, найти дефекты резины), когда система под них не обучена (например, ищет только дефекты дерева). Эту проблему можно решить с помощью дообучения на большом наборе данных (допустим, 10000 фотографий для 5 типов дефектов), но можно сократить его объем за счет выбора архитектуры сети.
Такие форматы хранения нейронных сетей, как ONNX и TorchSript , позволяют производить вычисления, обучение и добиваться при этом высокой производительности, но не предлагают возможностей для поиска архитектуры нейронной сети ( neural architecture search , NAS ). Для работы с архитектурами нейронных сетей требуется их эффективное сохранение.
Разработан формат хранения нейронных сетей с возможностями программным способом менять архитектуру сети и конвертировать его в другие форматы. Данный формат получил название FAMLINN – Formatted Auto Machine Learning Iterating Neural Network. Он позволяет не просто сохранить архитектуру сети в человеко-читаемом формате в виде ориентированного графа, но и удалять, добавлять и заменять его вершины оставляя инварианты по типам и размерностям на ребрах.
Разработанный формат внедрен в библиотеку и реализованы алгоритмы перегруппировки блоков нейронных сетей.
14.1 Хранение графа
В FAMLINN реализован граф, состоящий из вершин – вычислителей, и ребер, хранящих результаты. Для реализации этой идеи использовался объектно-ориентированный подход. Опишем основные составляющие системы.
Реализован объект Container , который можно создать, записывать в него данные и читать из него данные. Этот контейнер будет расположен на каждом ребре нашего графа. Объекты этого типа будут находиться в хранилище Storage , которое умеет создавать Container , находить их, а также возвращать контейнеры, которые являются первым, или же контейнером для входных данных, и последним, или же контейнером, содержащим результат вычисления нейронной сети.
Далее реализован объект Node , который является вершиной графа. Он будет хранить в себе список контейнеров, из которых ему следует брать данные, контейнер, в который ему требуется положить результат, и объект Evaluator . Этот объект содержит в себе функцию вычисления данной вершины. От него требуется только уметь вычислять, и по возможности генерировать собственный код для решения задачи генерации кода сети при конвертации (об этом в следующем пункте).
Объекты типа Node привязаны к Storage , взаимодействуя с которым они осуществляют операции с Container . Node содержит в себе информацию о ребрах через индексы контейнеров, поэтому список Node и связанный с ними Storage образуют класс NeuralNetwork . Этот класс умеет вычислять целевую функцию сети, и изменять архитектуру. Подробная реализация всех операций над архитектурой была описана выше, в библиотеке на момент написания работы находятся только операции для построения сети, а именно – добавить объект в конец.
Класс NeuralNetwork позволяет создавать нейронные сети по архитектуре через добавление функций и констант. Так как задан ориентированный ацикличный граф, в порядке его топологической сортировки можно добавлять константы, а также функции, оперирующие результатами вычисления других вершин, передавая их номера в инициализирующую новую вершину функцию.
Для работы в контексте фреймворка PyTorch был реализован класс FAMLINN , который наследуется от класса NeuralNetwork , поддерживая все его операции, и дополнительно позволяет инициализироваться от существующей PyTorch сети, копируя её архитектуру, а также генерировать PyTorch код сети, которая является текущей архитектурой, и при этом сохранять веса, имеющиеся в сети.
14.2 Конвертация в PyTorch
Для автоматизации построения модели данных требуется разработать формальный подход, позволяющий построить модель данных по реализации алгоритма. Однако в общем случае это трудно решаемая задача. Поэтому будет предложено решение для конвертации в формат TorchScript и обратной. Так как этот формат динамический, и его архитектура задается функцией вычисления через модули, то он позволяет совершать вычисления вне дочерних модулей, совершая операции непосредственно над данными как исполняемый код, а не часть нейронной сети. Для того чтобы такие операции можно было отследить, все тензорные операции были продублированы соответствующим модулем формата FAMLINN , который также совместим с PyTorch . Важно отметить, сами тензорные операции остаются как часть архитектуры, но они выражаются в явном виде через классовые обертки. Более того, в процессе внедрения было замечено, что для достижения похожих целей исследователями создаются такие же объекты классов, а именно для удобной агрегации модульных операций в последовательные блоки, которые также исключают чистые тензорные операции.
Необходимым условием для конвертации является наличие хотя бы одного аргумента сети. Язык Python является интерпретируемым, и можно говорить о том, что после проверки синтаксической корректности мы имеем только строку, и мы не можем для нее решать задачу останова [20]. То есть мы не можем утверждать, что данная программа завершается и задает конечную архитектуру, а также сходится по типам. При наличии аргумента мы способны запустить сеть, отловить вызовы всех функций, и восстановить ту часть архитектуры, по которой прошел данный аргумент. Это является существенным недостатком алгоритма конвертации, но в общем случае эта задача не может быть решена в рамках данной библиотеки.
Для конвертации алгоритм запускает вычисление целевой функции сети, при этом отслеживая все вызовы подмодулей. Так как мы явно запретили операции с тензорами, все вычисления проходят через дочерние модули. В библиотеке PyTorch есть встроенные средства получения порядка вычисления функции прямого распространения в строковом виде. Получив этот порядок, мы его разбираем регулярными выражениями, идем по нему, рекурсивно достраивая граф внутри каждого вложенного компонента и достраивая ребра между входами и выходами этих вложенных модулей. Рекурсия заканчивается на атомарных компонентах библиотеки PyTorch , которые оборачиваются в объект Evaluator для использования в FAMLINN.
Реализация этого алгоритма базируется на двух основных процедурах. Получение списка всех слоев сети позволяет определить множество вершин. Множество ребер требуется установить. И первая реализация использовала при этом скрытую функциональность модуля PyTorch , а конкретно функцию torch.jit._trase . Эта функция позволяла получить внутренний граф исполнения модуля, после чего он оптимизировался через torch.onnx.optimize_trace . То есть последовательность внутренних вызовов функций модуля оптимизировалась для конвертации в ONNX , однако вместо этого происходило сопоставление списка ребер с уже выявленным списком вершин. Данный подход имел существенные недостатки в универсальности при конвертации, а также опирался на ONNX функции, множество которых не обязательно может совпадать с PyTorch.
Для исправления всех этих недостатков пришлось использовать другой, публичный функционал библиотеки, а именно функцию torch.jit.trace , которая позволяет получить граф исполнения не всей архитектуры, а только функции прямого распространения конкретного модуля.
Именно использование встроенных в библиотеку PyTorch способов трассировки исполнения функции прямого распространения для модуля накладывает ограничения на возможности применения библиотеки. Данная задача может быть решена более качественно, что потребует значительно больше ресурсов.
Во-первых, так как архитектура задается функцией распространения, а она является исполняемым кодом, то будучи уверенным в его корректности есть способы более детального анализа производимых действий на уровне интерпретатора, что является крайне сложным и, вероятно, не надежным способом анализа архитектуры.
Во-вторых, разные программируемые конструкции, такие как циклы и создание дополнительных структур данных либо записи в поля класса, создают дополнительную, трудно поддающуюся анализу сложность, которая не относится к архитектуре, но может быть реализована при функциональном задании архитектуры. По этой причине в формат TorchScript введены специальные требования на чистоту функции forward и независимость способа исполнения от аргументов. Однако проверки этих инвариантов не производится, и при их нарушении поведение программы не может быть определено, как и конвертора.
Для генерации кода и сохранения весов мы обходим граф, сохраняем в отдельный файл параметры лежащего внутри Evaluator компонента, и дописываем в конструктор нейронной сети и её функцию прямого распространения строки, соответствующие её вычислению. Так как каждой вершине соответствует её номер, пронумерованы файлы с параметрами, а также сами вершины в сгенерированном коде, то можно добавить в этот код функцию считывания и инициализации соответствующих компонентов соответствующими весами.
Также важным остается тот факт, что архитектуры были доработаны для конвертации. В них были заменены чистые операции с тензорами на их обертки и функциональные PyTorch компоненты на их модульные аналоги.
Рисунок 14.1 - Иллюстрация изменений кода LeNet
На рисунке 14.1 показаны изменения, которые необходимо внести в реализацию LeNet для возможной конвертации. Слева указана исходная реализация нейронной сети. В ней присутствует модуль nnf , или же функциональные операции PyTorch , а также операция flatten над тензором. Справа все функциональные операции заменены на соответствующие им модули и создан модуль, выполняющий операцию flatten.
14.3 Сравнение с аналогами
Изучим поведение библиотеки на разных архитектурах и проведем сравнительный анализ с другими форматами по потреблению ресурсов, чтобы сделать вывод о проделанной работе и наметить точки для дальнейших улучшений. Данная библиотека была протестирована на 5 архитектурах нейронных сетей, а именно: LeNet , ResNet 101, VGG 19, UNet , генеративная и дискриминирующая части архитектуры DCGAN.
Опишем процедуру исследования корректности библиотеки FAMLINN при работе с архитектурами:
1. Для всех архитектур имелась PyTorch реализация, которая была откорректирована, чтобы в ней не содержалось операций над тензорами.
2. Генерировался аргумент целевой функции. Для всех экспериментов фиксировалось ключ генератора псевдослучайных чисел для воспроизводимости результатов.
3. Нейронная сеть конструировалась, при этом она инициализировалась случайными весами. Вычисляли значение целевой функции на сгенерированном аргументе.
4. Сеть конвертировалась в FAMLINN . Получали результат вычисления на аргументе. Проверялось, что значение такое же как в пункте 3.
5. Сеть, загруженная в FAMLINN , сбрасывалась на диск. То есть генерировался PyTorch код сети, и сохранялись её веса.
6. Запускался сгенерированный код, веса этой сети считывались из файлов. Получали результат вычисления на аргументе.
7. Полученная на 6 шаге сеть конвертировалась в FAMLINN , и вычислялась на всё том же аргументе. После чего сравнивались значения из этого и 6 пунктов.
В результате численные значение на 3, 4, 6 и 7 шаге совпадали для всех исследованных сетей, на основании чего был сделан вывод о корректности работы алгоритма конвертации. Тут стоит отметить, что дополнительным маркером корректности также является совпадение всех аргументов составных функций по типам и размерности. Факт успешного вычисления подтверждает это совпадение.
14.4. Потребляемые ресурсы
Были проведены замеры времени исполнения пунктов тестирования,
соотношения занимаемой памяти и производительности сравнительно ONNX . Результаты приведены в таблице 14.1.
Таблица 14.1 - Время тестирования
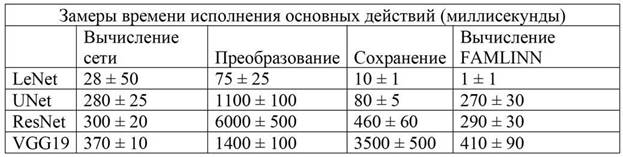
Были произведены замеры пунктов 3, 4, 5 и 6. Время вычисления исходной сети сопоставимо с временем вычисления в FAMLINN , что косвенно подтверждает факт вычисления того же множества функций. Конвертация и сохранение сети на диск занимают разумное время.
Таблица 14.2 - Производительность ONNX

По сравнению с ONNX время на конвертацию у FAMLINN меньше, так как его структура более легковесная, он не использует сложные protobuf файлы и опирается на встроенные и оптимизированные в PyTorch алгоритмы сохранения объектов. Однако время исполнения FAMLINN и оригинальной сети на порядок хуже, чем у ONNX . Это может объясняться тем, что ONNX производит оптимизацию времени исполнения, что является важным требованием в области его применимости. Не исключен вариант, что запуски из таблиц 9.4.1 и 9.4.2 были произведены в разном окружении, например если библиотека ONNX умеет запускаться на графических сопроцессорах и видеокартах. Также может сказываться низкое качество экспериментов, так как в одном случае замеры включают в себя время загрузки, а в другом разделены.
Таблица 14.3 - Объем занимаемой памяти

Сравнивая соотношения занимаемой памяти между оригинальной сетью, сохраненной стандартным способом этой библиотекой и FAMLINN получаем, что чем больше вес самой сети, тем меньшим становится расхождения. Но даже на небольших архитектурах расхождение менее 4% (см. таблицу 14.3). Расхождение может объясняться накладными расходами операционной системы на поддержание структуры файлов, так как FAMLINN создает по файлу на каждый модуль, а PyTorch сохраняет всю сеть в один файл.
14.5 Выводы
На данном этапе был предложен и реализован подход хранения нейронных сетей с учетом возможности работы с архитектурой. Данный формат работы позволяет добиться сопоставимых по эффективности потребления ресурсов возможностей для хранения, при этом предоставляет расширенный функционал.
В новом формате сочетается простота хранения архитектуры для исследований, возможность работы с весами и параметрами, а также возможность вычисления целевой функции для прикладного использования. А также формат хорошо подходит для конвертации между различными способами представления нейронных сетей, так как имеет своей основой простую абстрактную модель.
Разработанный формат внедрен в библиотеку.
15. Оценка разработанной библиотеки
В процессе реализации различных моделей и алгоритмов библиотеки, они применялись и тестировались в реальных проектах, результаты которых высоко оценивались руководителями. Подробное описание всех модулей библиотеки описано в текущем документе, а исходный код опубликован в соответствующем github-репозитории.
15.1 Проведение исследований, оценка эффективности разработанных алгоритмов, анализ способов их улучшения
Для всех модулей библиотеки проведено сравнение полученных результатов и их оценка, описанные в соответствующих разделах. Реализованные алгоритмы на практике удовлетворяют заявленным критериям качества. Анализ способов улучшения производился в ходе реализации, в основном в виде выбора нейронных архитектур и алгоритмов, а также работы с данными.
Разработанные модули адаптированы к реальным условиям производства – зашумленной среде, тряске. Также внедрен формат FAMLIN , что позволит ускорить работу модулей библиотеки.
15.2 Тестирование, оптимизация скорости работы алгоритмов
Тестирование проведено в одних условиях с одинаковой структурой конвейеров на видеокарте RTX 3070 (мобильной версии), а также полноценной карте RTX 3090. Некоторые алгоритмы были адаптированы для работы под тензорные процессоры ( TPU).
Таблица 15.1 - Результаты тестирования модулей библиотеки
|
Оценка / Алгоритм |
Положение и расстояние объектов в пространстве |
Распознавание номеров |
Подсчёт объектов |
|
Точность |
Погрешность до 10 мм на расстоянии до 0.7м |
Accuracy: 96% |
AP: 51% |
|
Скорость |
3 кадра в секунду |
15 кадров в секунду |
7 кадров в секунду |
Пример выполнения алгоритма по определению положения и расстояния объектов в пространстве показан на рисунке 15.1.

Рисунок. 15.1 - Пример расчёта определения расстояния в пикселях между двумя объектами.
Скорость работы, каждого компонента для этой задачи представлен на рисунке 15.2.
Рисунок
15.2 - Логи со скоростью работы для задачи определения расстояния.
![]()
- SourceMuxer - чтение и объединение кадров.
- ModelDepth – определение глубины по кадрам.
- ManualROICorrelationBasedTracker – слежение за уже найденными объектами.
- DistanceCalculator – подсчёт раастояния между объектами.
- DepthPainter – отрисовка карт глубины.
- BBoxPainter – отрисовка ограничивающих рамок.
- Tiler – объединение нескольких кадров в один.
- DisplayComponent – вывод результата.
Пример
выполнения алгоритма по распознаванию номеров показан на рисунке 15.3.
![]()
Рисунок 15.3 - Пример распознавания номеров на машине.
Скорость
работы, каждого компонента для этой задачи представлен на рисунке 15.4.
![]()
Рисунок 15.4 - Логи со скоростью работы для задачи распознавания номеров.
- SourceMuxer - чтение и объединение кадров.
- ModelDetectionDiffLabels – распознавание и детекция номеров
- BBoxPainter – отрисовка ограничивающих рамок.
- Tiler – объединение нескольких кадров в один.
- DisplayComponent – вывод результата.
Пример выполнения алгоритма по подсчёту объектов показан на рисунке 15.5.

Рисунок 15.5 - Пример подсчёта машин на видео, пересекших прямую.
Скорость работы, каждого компонента для этой задачи представлен на рисунке 15.6.
Рисунок
15.6 - Логи со скоростью работы для задачи подсчёта объектов.
![]()
- SourceMuxer - чтение и объединение кадров.
- ModelDetection – детекция объектов.
- Counter – подсчёт объектов.
- BBoxPainter – отрисовка ограничивающих рамок.
- Tiler – объединение нескольких кадров в один.
- DisplayComponent – вывод результата.
Подсчёт объектов построен на базе yolo large , поэтому используя yolo или yolo small , повысится и скорость работы, но уменьшится точность.
На данный момент, как видно из логов о работе пайплайнов, узким звеном является скорость выполнения моделей. Их архитектура выбирала так, чтобы они были теоретически оптимальны. В дальнейшем модули будут оптимизированы за счет использования разработанного формата сохранения сетей FAMLINN .
16. Применений алгоритмов к уже реализованным проектам и оценка качества.
16.1 Применение алгоритмов расчёта положения объектов в пространстве
Алгоритмы расчёта положения в пространстве применены к проекту управления роботическим манипулятором-рукой в пространстве. Рука находится в опущенном положении и необходимо осуществить подключение приёмника, размещённого на конце манипулятора, к розетке, размещенной на стене. Положение руки относительно розетки не фиксируется. Выбрано использование двух камер для измерения расстояния по трём осям. Необходимо измерения расстояния между краем розетки и приёмником.

Рисунок 16.1 - Манипулятор Promobot Rooky.
Использован модуль детекции, обученный на распознавание конца руки и розетки на стене. Далее осуществлён расчёт расстояния по изображению (в пикселях), расстояние переведёно в пространственные координаты (разность координат). В качестве множителя использован размер розетки (вместо глубины), так как он известен. В качестве точки отсчёта используется точка крепления руки. Камеры закреплены сбоку от руки и сверху манипулятора (перпендикулярно стене).

Рисунок 16.2 - демонстрация детекции и расчёта расстояния
Полученный расчёт использован для изменения углов поворотов суставов роботического манипулятора для подъем и приближения. Перемещения по осям z и y (приближение и подъём руки) осуществлен с помощью формул прямой кинематики.
![]()
![]()
Где L 1 - длина “плеча” манипулятора, L 2 - длина “предплечья” манипулятора, Q 1 - поворот плеча, Q 2 - поворот локтя. Перемещение по оси X осуществлено с помощью поворота плечевого сустава по формуле:
![]()
Где Q 3 - угол поворота, ds - расстояния по горизонтали до объекта с верхней камеры, y - расстояние до розетки.
16.2 Применение алгоритмов гранулометрии
Алгоритмы определения размеров объектов (гранулометрия) применены для определения размеров пузырей флотации для компании “Норникель”.
Флотация – процесс переработки и обогащения руды, при котором гидрофобные частицы отделяются от гидрофильных путём закрепления на границе раздела фаз (двух жидкостей). Процесс используется при отделении ценных металлов от необогащенной руды и разделении частиц различной крупности. При пенной флотации через смесь частиц руды с водой пропускается поток воздуха, вследствие чего на поверхности образуется пена, насыщенная необходимыми компонента. Пена отделяется от жидкости и высушивается. Разновидности пенной флотации применяются так же в пищевой промышленности и в отрасли переработки целлюлозы.
По существующим методикам был подготовлен
датасет для обучения с помощью метода водораздела (рис. 16.3)

Рисунок 16.3 - подготовка датасета для обучения
На основе полученного датасета с мануальными исправления ошибочно выбранных пузерый осуществлено обучение нейронной сети U-net .

Рисунок 16.4 - полученные результаты
Проведена оценка точности работы алгоритмов на наборе из десяти изображений с помощью метрики IoU ( Intersection over Union ), рассчитываемая как отношения площади пересечения объектов к площади объединения объектов. Полученная усредненная точность: 0,91, что говорит о высоком качестве работы алгоритмов.
17. Сравнение реализованной библиотеки с аналогами.
Преимущества библиотеки cvflow по сравнению с DeepStream:
1) Расширяемость: В отличие от DeepStream , cvflow обладает высоким уровнем расширяемости, что позволяет разработчикам легко настраивать и адаптировать библиотеку под узкоспециализированные или специфические приложения видеоанализа. Это дает большую свободу выбора и возможность более гибкой настройки.
2) Простая структура лицензирования: В отличие от DeepStream , cvflow предлагает прозрачную и простую структуру лицензирования. Это особенно важно для организаций с ограниченным бюджетом или для тех, кто предпочитает простые варианты лицензирования без дополнительных расходов на расширенные функции или развертывание на нескольких системах.
3) Поддержка сообщества: cvflow , будучи построенной на основе открытого исходного кода, может привлечь большее сообщество пользователей и разработчиков, что обеспечивает более широкую поддержку и доступ к ресурсам. Сообщество также может обеспечить более быстрое реагирование на проблемы или запросы функций.
4) Более низкий порог входа для новичков: cvflow предоставляет более простой и доступный интерфейс, что делает ее более подходящей для разработчиков, новичков в области видеоаналитики или программирования на GPU . Это облегчает процесс обучения и использования библиотеки, особенно для организаций, ищущих более простое и удобное решение.
Преимущества библиотеки cvflow по сравнению с mmdetection:
1) Удобная кривая обучения: cvflow предоставляет простой и интуитивно понятный интерфейс для обучения моделей. Это особенно полезно для разработчиков, которые впервые знакомятся с задачами обнаружения объектов и не обладают глубоким пониманием глубокого обучения или специфических фреймворков. cvflow упрощает процесс обучения и настройки моделей.
2) Встроенная обработка видеопотока: В отличие от mmdetection , cvflow предлагает встроенную функциональность для обработки видеопотока в реальном времени. Это позволяет эффективно работать с видеоданными и выполнять специализированные задачи видеоанализа, делая библиотеку более подходящей для таких приложений.
3) Простая конфигурация и настройка: cvflow предоставляет удобный интерфейс для конфигурации и настройки моделей, минимизируя сложность и время, необходимые для достижения желаемых результатов. Разработчики могут легко изменять параметры и настраивать модели, ускоряя процесс разработки и тонкой настройки.
Таким образом, библиотека cvflow обладает рядом преимуществ по сравнению с DeepStream и mmdetection , включая высокую расширяемость, простую структуру лицензирования, поддержку сообщества, более низкий порог входа для новичков, удобную кривую обучения, встроенную обработку видеопотока и простую конфигурацию и настройку.
Заключение
1. Описание результатов
Реализована общая архитектура библиотеки, предоставляющей полный инструментарий для построения конвейеров самых часто используемых задач компьютерного зрения. При разработке архитектуры и ее реализации были учтены требования к считыванию видеопотока, работе в реальном времени, решении задач детекции, классификации и сегментации и многие другие. Достигнута масштабируемость и гибкость функционала фреймворка.
Изучены открытые источники данных с учетом требований к данным. По двум из пяти задач найдено достаточное количество данных и соответствующая разметка. Для решения остальных задач собрано и размечено 5 наборов необходимых изображений и видеозаписей.
Были разработаны алгоритмы распознавания положения производственных объектов в пространстве и расстояний между ними, алгоритмы детекции дефектов поверхностей, алгоритмы распознавания номеров объектов, алгоритмы анализа перемещений объектов и алгоритмы определения размеров объектов. По всем алгоритмам достигнуты требуемые показатели, кроме анализа местоположения, где указанной в заявке точности не позволили достичь характеристики объективов видеокамер. Итого, заявленная в рамках гранта F 1-мера в задачах многоклассовой классификации более 0,7 достигнута, подробнее в таблице.
Таблица - Достигнутая точность в задачах многоклассовой и бинарной классификации.
|
Задача |
Число классов |
Точность |
|
Классификация дефектов на дереве |
7 |
0,79 |
|
Классификация дефектов на стали |
5 |
0,97 |
|
Классификация дефектов на мраморе |
5 |
0,91 |
|
Классификация транспортных средств по типу кузова |
8 |
0,96 |
|
Классификация руды на конвейере |
2 |
0,96 |
|
Классификация типа материала |
3 |
0,83 |
Была заявлена точность локализации 0,5 мм, но не были указаны характеристики камеры и расстояние до объектов. При расстоянии до объектов в 70 см получена точность в 1 см, что является успешным результатом и применено на практике. Точность распознавания номеров объектов более 95%. На основе модели SSD была построена модель для детекции дефектов на основе малого количества данных. Это было достигнуто, благодаря использованию архитектуры сиамских нейросетей и обучению на нескольких датасетах. Соответственно, решается проблема недостатка данных в сфере дефектоскопии.
Разработан формат сохранения нейронной сети FAMLINN , позволяющий настраивать архитектуры нейронных сетей.
Разрабатываемые на данном этапе решения успешно внедрены на предприятиях Евраз, Норникель, Русал.
2. Перечень направлений прикладного использования
Универсальность системы позволяет использовать ее для управления совершенно разными производствами, связанными с созданием физических объектов (горнодобывающая промышленность, мебельная промышленности, ювелирная промышленность, обработка металла и так далее). Система построена для анализа видеопотока, для ее запуска потребуется видеокамера, установленная в месте, где требуется контроль или управление производством, и компьютер с видеокартой, что в современном мире не требует больших затрат по сравнению с зарплатой сотрудников, которые могли бы создать индивидуальное решение.
Прикладное использование библиотеки:
1) Распознавание дефектов и прочих образований на материале (металл, дерево, пластик, пленка на жидкости).
2) Распознавание положения объекта (детали производственного оборудования, человека, машины) в пространстве.
3) Распознавание категории объекта (тип транспортного средства, металла, дерева, и других материалов).
4) Распознавание номера объекта (автомобиля, вагона поезда, других объектов на производстве или в городской среде).
5) Анализ перемещения объектов (людей, машин и других) в пределах установленной области.
6) Распознавание размеров объектов (камни, пена).
7 ) Решение вышеперечисленных задач в условиях сложной окружающей среды.
Реализованы алгоритмы определения положения объекта в пространстве и распознавания расстояния до объектов и между объектами с использованием моно- и стереозрения. Алгоритмы работают с небольшими произвольными объектами. На расстояниях до одного метра достигается точность до 5 мм, более одного метра - до 1 см. Алгоритмы доработаны и протестированы в сложных условиях и сохраняют свою точность. На расстоянии менее 30 см невозможно осуществить построение карты глубины из-за технических особенностей камеры (межфокусное расстояние). Алгоритмы определения объектов в пространстве применены при работе над проектом Конструкторского бюро “Раскат”. Алгоритмы распознавания размеров объектов применены при работе над автоматизацией процесса анализа флотации. Демонстрация примера https://github.com/MLFreelib/cvflow/tree/main/examples/granulometry .
3. Ссылка в сети Интернет на публикацию открытой библиотеки в публичном репозитории
https://github.com/MLFreelib/cvflow
4. Пример новых вариантов использования кода открытой библиотеки
Разработанные алгоритмы могут применяться на производствах, требующих точности при передвижении деталей, например, при определении расстояния между ударными установками, при технологических процессах в металлургии, требующих определение точного расстояния в моменте. Так же методы могут использоваться для управления манипуляторами.
В перспективе возможно повышение точности работы библиотеки с помощью создания собственного датасета и сбором реальных данных стереометрии.
Возможно добучение модели на других данных для решения задач, выходящих за рамки дефектоскопии. Это позволит решать узконаправленные задачи с минимальным количеством данных.
5. Ссылка в сети Интернет на открытую лицензию, по которой предоставляется доступ к использованию открытой библиотеки
https://github.com/MLFreelib/cvflow/blob/main/LICENSE
6. Ссылка в сети Интернет на инструкцию по работе (туториал) с открытой библиотекой
https://github.com/MLFreelib/cvflow#readme
7. Минимальные технические требования для запуска и использования открытой библиотеки
Минимальные технические требования для запуска
i3/5 с частотой от 2.2 GHz, NVIDIA GeForce GT 520, CUDA , Оперативная память: 4 GB, Свободное место на диске 1 GB, ОС не ниже Linux Lite, Anaconda 2.3.2
Минимальные технические требования для использования открытой библиотеки:
- Камера, видео, изображения
- Компьютер с GPU c 8Гб памяти.
Для более быстрой работы необходима, как можно более мощная видеокарта. Для большей точности на производстве необходима камера с хорошим качеством и поддержкой от 30 кадров в секунду.
Для использования алгоритмов распознавания объектов в пространстве и расстояния между объектами минимальными требованиями является наличие стереокамеры или пары откалиброванных камер.
Список использованных источников
1. Geiger A . и др. Vision meets robotics: The KITTI dataset // The International Journal of Robotics Research. 2013. Т. 32. № 11. С. 1231–1237.
2. Shamsafar F. и др. MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching [Электронный ресурс]. URL: https://arxiv.org/abs/2108.09770 .
3. Garg D. и др. Wasserstein Distances for Stereo Disparity Estimation [Электронный ресурс]. URL: https://arxiv.org/abs/2007.03085 .
4. Panaretos V. M., Zemel Y. Statistical Aspects of Wasserstein Distances // Annual Review of Statistics and Its Application. 2019. Т. 6. № 1. С. 405–431.
5. Mayer N. и др. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation // 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). : IEEE, 2016.
6. Gonzalez, M., Ballarin, V. Automatic marker determination algorithm for watershed segmentation using clustering // Latin American Applied Research. – 2009, July. – Vol. 39. – P. 225–229.
7. Ronneberger, O., Fischer, P., Brox, T. U-Net Convolutional Networks for Biomedical Image Segmentation // Medical Image Computing and Computer-Assisted Intervention (MICCAI). – Vol. 9351. – Springer, 2015. – P. 234–241. – (LNCS). – URL: http://lmb.informatik.uni-freiburg.de/ Publications/2015/RFB15a (дата обращения 05.05.2022).
8. Liu, X., Ore image segmentation method using U-Net and Res_Unet convolutional networks // RSC Adv. – 2020. – Vol. 10, Is. 16. – P. 9396–9406. –– URL: http://dx.doi.org/10.1039/C9RA05877J (дата обращения 14.05.2022).
9. Hamzeloo, E., Massinaei, M., Mehrshad, N. Estimation of particle size distribution on an industrial conveyor belt using image analysis and neural networks // Powder Technology. – 2014. – Vol. 261. – P. 185–190.
10. Bochkovskiy A., Wang C., Liao H. M. Yolov4: Optimal speed and accuracy of object detection // CoRR. — 2020. — Vol. abs/2004.10934. — arXiv : 2004.10934
11. Mask R-CNN / Kaiming He, Georgia Gkioxari, Piotr Doll ́ar, Ross B. Girshick // CoRR. — 2017. — Vol. abs/1703.06870. — arXiv : 1703.06870.
12. Dynamic head: Unifying object detection heads with attentions / Xiyang Dai, Yin- peng Chen, Bin Xiao et al. // CoRR. — 2021. — Vol. abs/2106.08322. — arXiv : 2106.08322.
13. End-to-end semi-supervised object detection with soft teacher / Mengde Xu, Zheng Zhang, Han Hu et al. // CoRR. — 2021. — Vol. abs/2106.09018. — arXiv : 2106.09018.
14. Attention is all you need / Ashish Vaswani, Noam Shazeer, Niki Par- mar et al. // Advances in Neural Information Processing Systems / Ed. by I. Guyon, U. Von Luxburg, S. Bengio et al. — Vol. 30. — Curran Associates, Inc., 2017. — Access mode: https://proceedings.neurips.cc/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
15. Glenn, Jocher ultralytics/yolov5: v6.1 - TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference / Jocher Glenn. — Текст : электронный // zenodo.org : [сайт]. — URL: https://github.com/ultralytics/yolov5 (дата обращения: 10.06.2022).
16. Visual object tracking using adaptive correlation filters / S. B. David. — Текст : электронный // researchgate.net : [сайт]. — URL: https://www.researchgate.net/publication/221362729_Visual_object_tracking_using_adaptive_correlation_filters (дата обращения: 10.06.2022).
17. Wojke N., Bewley A., Paulus D. Simple online and realtime tracking with a deep association metric //2017 IEEE international conference on image processing (ICIP). – IEEE, 2017. – С. 3645-3649.
18. Koch G. et al. Siamese neural networks for one-shot image recognition //ICML deep learning workshop. – 2015. – Т. 2. – С. 0.
19. Simonyan K., Zisserman A. Very deep convolutional networks for large-scale image recognition //arXiv preprint arXiv:1409.1556. – 2014.
20. Turing A. M. et al. On computable numbers, with an application to the Entscheidungsproblem //J. of Math. – 1936. – Т. 58. – №. 345-363. – С. 5.
21. Alabdulmohsin I., Neyshabur B., Zhai X. Revisiting neural scaling laws in language and vision // arXiv preprint arXiv:2209.06640. — 2022.
22. Salau A. O., Jain S. Feature extraction: a survey of the types, techniques, applications // 2019 international conference on signal processing and communication (ICSC). — IEEE. 2019. — С. 158–164.
23. A review on image feature extraction and representation techniques / D. Ping Tian [и др.] // International Journal of Multimedia and Ubiquitous Engineering. — 2013. — Т. 8, № 4. — С. 385–396.
24. Content-based image retrieval and feature extraction: a comprehensive review / A. Latif [и др.] // Mathematical problems in engineering. — 2019. — Т. 2019.
25. Roy K., Mukherjee J. Image similarity measure using color histogram, color coherence vector, and sobel method // International Journal of Science and Research (IJSR). — 2013. — Т. 2, № 1. — С. 538–543.
26. Ojala T., Pietikainen M., Harwood D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions // Proceedings of 12th International Conference on Pattern Recognition. Т. 2. — Los Alamitos, CA, USA : IEEE Computer Society, 10.1994. — С. 582, 583, 584, 585.
27. Dalal N., Triggs B. Histograms of oriented gradients for human detection // 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05). Т. 1. — Ieee. 2005. — С. 886–893.
28. Dosovitskiy A., Brox T. Inverting visual representations with convolutional networks // Proceedings of the IEEE conference on computer vision and pattern recognition. — 2016. — С. 4829–4837.
29. Rethinking the Inception Architecture for Computer Vision / C. Szegedy [и др.]. — 2015. — arXiv: 1512.00567 [cs.CV].
30. Jocher, G., Chaurasia, A., & Qiu, J. (2023). YOLO by Ultralytics (Version 8.0.0) [Computer software]. https://github.com/ultralytics/ultralytics