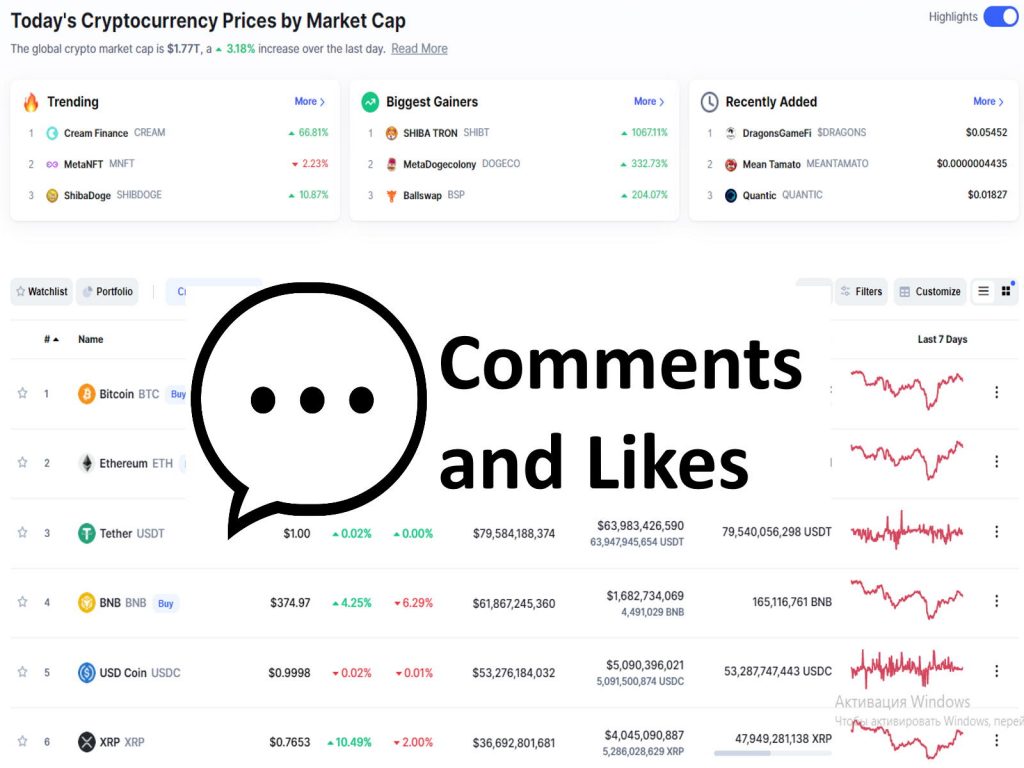
Прогнозная система характиристик публикаций
Прогнозная система характеристик публикаций (Views, Likes, Clicks, Comments, и т.д.)
Автоматизируйте работу с документами, обработку текстовой информации и речевых обращений
Информационный поиск, структурированное извлечение и классификация информации
Распознавание речи и диалогов, выявление речевых паттернов, ключевых фраз и тегов
Извлечение информации из сканов и фотографий документов, распознавание рукописного текста и документов на видео
Оптимизация клиентского сервиса, автоматизация коммуникаций и работы с данными

Интеллектуальный поиск информации во внутренней базе данных, веб-скраппинг (web scraping) автоматический поиск информации в интернете, агрегация в заданном формате (csv, json и другие)

Структурированное извлечение данных из документов, суммаризация текста в компактный вид, резюме, краткое содержание

Классификация по тематике, стилю, анализ тональности, проверка документов на соответствие определенным параметрам. Анализ ответов оператора (вежливо, грубо), отзывов и кометариев к статьям (положительный, отрицательный, нейтральный)

Извлечение ключевых слов, тегов, сущностей и речевых оборотов, выделение основных тем, положений и смысла

Анализ и проверка документов по различным критерием, соответствию закону страны, выявление сомнительных и подозрительных пунктов

Анализ текста на разных языках и разного уровня структуризации и автоматический перевод на любые языки
Автоматизируйте распознавание и проверку документов, повышайте эффективность процессов

Извлечение информации из документов любых типов и форматов: PDF, JPG/JPEG, PNG, TIFF, WEBP

Структурированное извлечение данных из документов, распознавание шаблонных документов и базовых атрибутов

Чтение кириллицы и латиницы, извлечение информации из сканов и фотографий, содержащих рукописный текст

Извлечение информации и распознавание текста из различных кадров на видео, проверка документов при видеоконтроле
Виртуальные ассистенты и кастомизированные бизнес-боты на основе популярных языковых моделей (LLM)
Прогнозная система характеристик публикаций (Views, Likes, Clicks, Comments, и т.д.)

Иерархическая система классификации веб-сайтов по категориям
Система генерации доменных имен по текстовому описанию

Поисковая информационная система (локальная LLM) для внутренних документных баз данных компании

Системы поиска информации, способные находить конкретные статьи в обширной базе знаний с помощью текстовых описаний
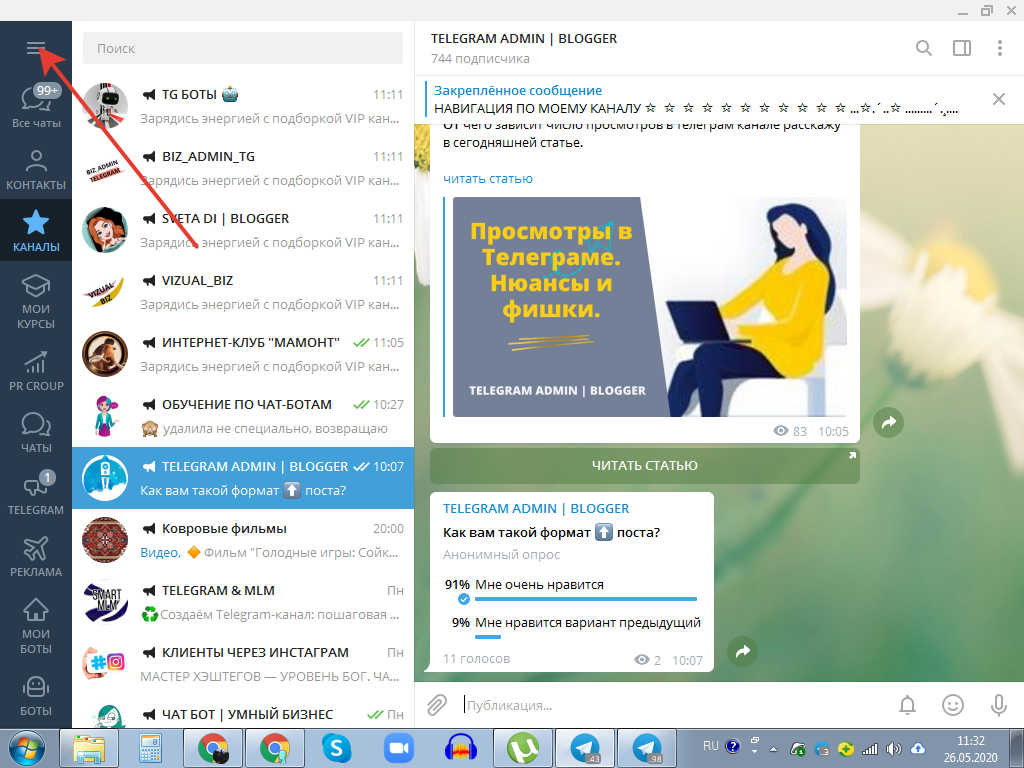
Система анализа и выделения новых популярных тем на базе данных телеграмм каналов
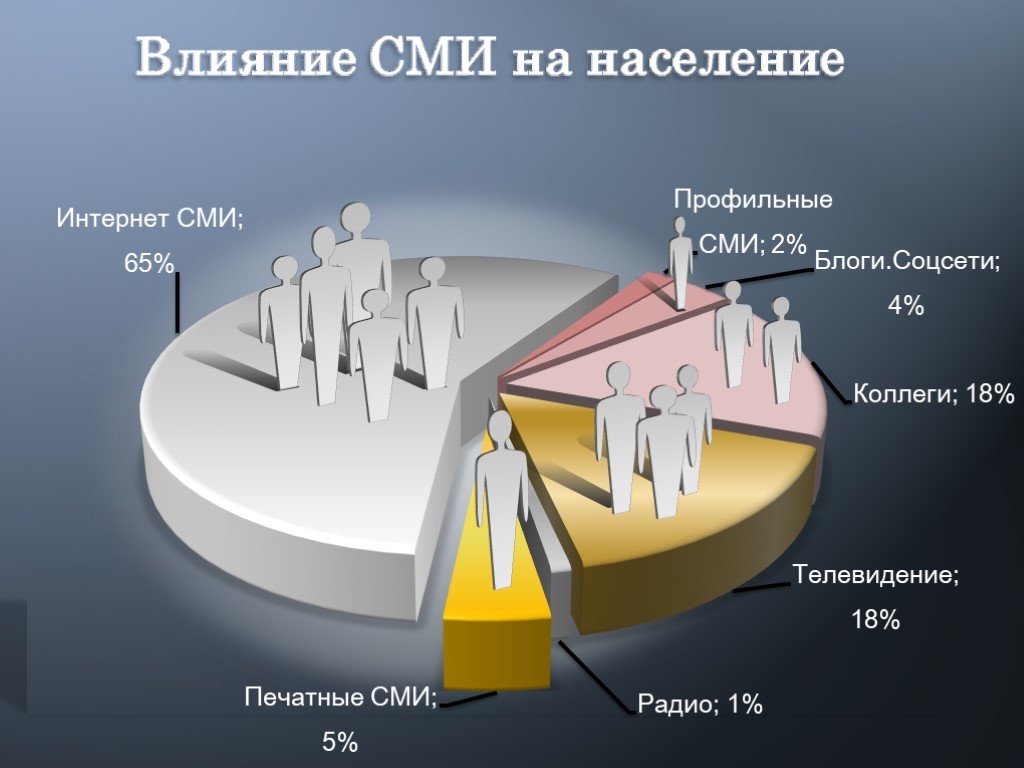
Система прогнозирования тенденций общественных настроений по заданным тематикам

