1. Прогнозирование наработки на отказ нефтедобывающего оборудования
- Категория: Прогнозные системы
- Клиент: Газпром нефть
- Дата: 2018
Разработать методику прогнозирования средней наработки на отказ (СНО) внутрискважинного оборудования и планирования межремонтного периода (МРП) работы скважин, а также систему определения технического предела работы оборудования в скважине. Общая задача: Создание системы прогнозирования средней наработки на отказ (СНО) оборудования по группе заданных параметров.
Функция распределения
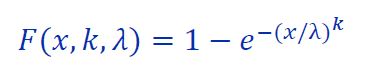
Постановка задачи
Используемые признаки входных данных, описывающих нефтедобывающие скважины
- Численные: 'Напор', 'Глубина спуска', 'Произв.', Q ж (режим)', Q н (режим)', '% воды (режим)', ' H дин (режим)', Pзаб(режим), Pпр(режим)
- Категориальные (полная бинаризация ): 'Причина (предыдущая остановка)', 'Принадлежность', 'Подрядчик ЭПУ', 'Тип насоса', 'Режим работы', 'ЭЦН, завод изготовитель', 'Протектор, завод изготовитель', 'ПЭД, завод изготовитель', 'Кабель, завод изготовитель‘
Целевой признак: наработка на отказ (в днях) '
Проблема: много пропущенных данных
Начальная обработка входных данных
Используемые признаки дополнительных таблиц:
- Используются только данные по насосам
- Численные ::'Номинал Q', ' Левая зона', 'Правая зона', 'Номинал F', 'Q', ' Н', ' Мощн ', 'КПД
- Категориальные (полная бинаризация): 'VENDOR', 'TYPERU', 'TYPEFGN'
Использованный классификатор: Catboost
Результат после начальной обработки (SMAPE): 0.734
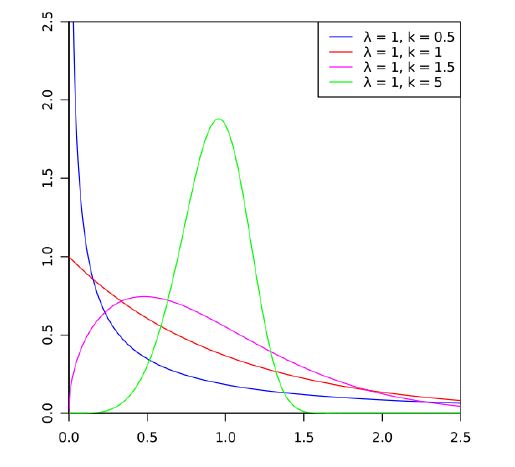
Двухпараметрическое распределение Вейбулла
Нормальное распределение является частным случаем двухпараметрического распределения Вейбулла, которое описывает наработку до отказа с учетом коэффициента k, характеризующую изменение интенсивности отказов во времени.
Добавление признаков распределения Вейбулла по месторождениям
- Для каждого месторождения обучающей выборки по целевому признаку (НнО) автоматически рассчитываются параметры распределения Вейбулла (коэффициент формы, матожидание, дисперсия)
- Указанные параметры добавляются, в зависимости от месторождения, в обучающую и тестовую выборки.
Результат с признаками Вейбулла (SMAPE): 0.732
Результат после настройки параметров catboost (SMAPE): 0.726
2. Прогнозная система отказа тяговыхэлектродвигателей электровозов 2ЭС6
- Категория: Прогнозные системы
- Клиент: Синара Транспортные Машины
- Дата: 2019
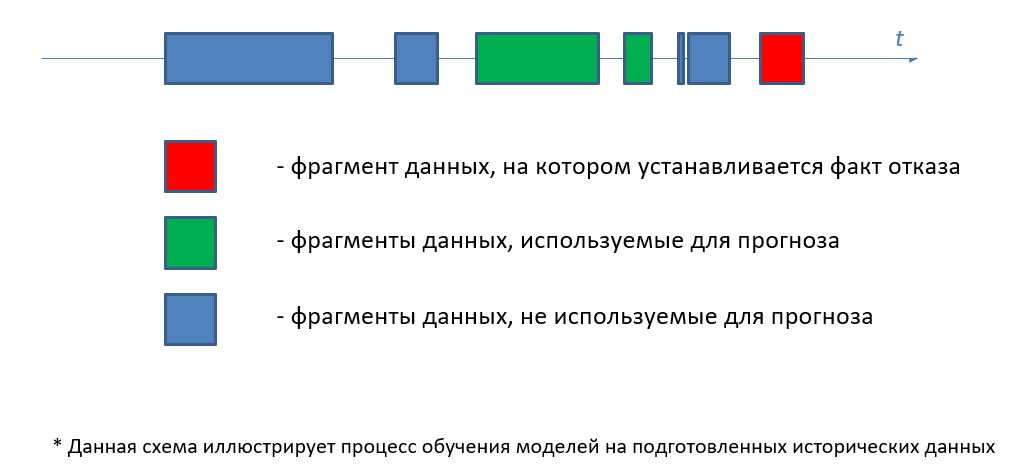
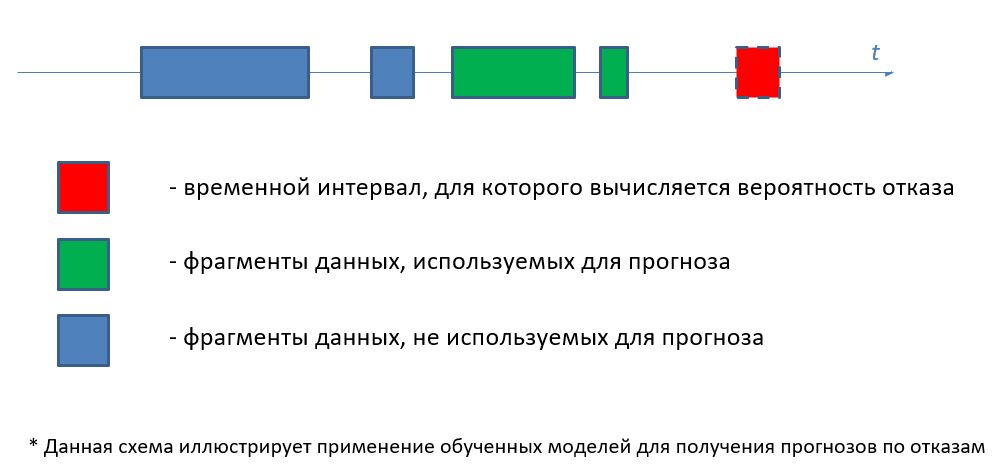
Разработанные модели позволяют делать следующие прогнозы:
- Прогноз вероятности отказа в течении в среднем 36 часов непрерывной работы через 1 день от даты прогноза с использованием данных за 6 дней до даты прогноза
- То же, через 7 дней с использованием данных за 7 дней
- То же, через 14 дней с использованием данных за 16 дней
- То же, через 30 дней с использованием данных за 30 дней
В процессе анализа предоставленных данных, были обнаружены следующие особенности, влияющие на конечные результаты прогнозов
- Фрагментация данных
- Выбросы в данных
- Шумы
- Смещение выборки в сторону отказов
Ниже представлены метрики roc-auc оценки качества моделей прогноза:
- Прогноз через 1 день: roc-auc: 0.75
- Прогноз через 7 дней: roc-auc: 0.7
- Прогноз через 14 дней: roc-auc: 0.65
- Прогноз через 30 дней: roc-auc: 0.6
3. Система прогнозирования останова при производстве пероксидноймарки
- Категория: Прогнозные системы
- Клиент: Сибур
- Дата: 2019
При производстве пероксидной марки полипропилена последний этап заключается в нарезке гранулята. Бывает так, что на ножи начинают налипать агломераты в результате ножи начинают отъезжать от фильеры, процесс деградирует и происходит останов оборудования. Это большие потери для производства. Процесс деградации косвенно можно отследить по наличию агломератов на вибросите. На базе данных телеметрии (за год), по а также данным по остановам экструдера разработать систему предсказывающая останов.
Общая задача: использовать эти данные для разработки и развертывания прогнозной системы, способной предвидеть отключения оборудования.
В рамках пилотного проекта мы успешно реализовали LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) модели.
Результаты (LSTM):
- Training Accuracy = 0.97
- Test Accuracy = 0.89
Результаты (GRU):
- Accuracy = 1.000
- Test Accuracy = 0.87
Эти результаты могут быть дополнительно улучшены за счет постоянного сотрудничества со специалистами в предметной области и внедрения более совершенных методов предварительной обработки данных.