Распознавание текста, номеров, QR-кодов и промышленных маркировок
Подборка проектов по OCR и видеоаналитике: от многоязычного распознавания текста на мобильных устройствах до номерных знаков, вагонов, QR-кодов, штрихкодов и маркировок на промышленных материалах.
Многоязычное распознавание текста для мобильных устройств

Задача
Требовалось улучшить детекцию и распознавание текста для нескольких письменностей: арабской, китайской, корейской, японской, латинской и кириллической. Отдельное условие — сохранить совместимость с ограничениями мобильного NPU и не ухудшить качество по другим языкам.
- улучшить детекцию и распознавание арабского языка;
- повысить качество распознавания китайского и английского текста;
- сохранить единую модель для нескольких письменностей;
- уложить модель в ограничения по размеру и производительности.
Ключевые результаты
Были протестированы SegLink на DenseNet и AdvancedEAST. Для китайского и английского языков решение STATANLY показало F1-score 0.939 против 0.908 у baseline.
Примеры детекции текста






Метрики и ограничения
| Решение | F1-score |
|---|---|
| Baseline (NLPR) | 0.908 |
| Statanly | 0.939 |
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.84 | 0.86 | 0.82 |
| AdvancedEAST | 0.85 | 0.97 | 0.76 |
| Baseline (HQ) | 0.82 | 0.92 | 0.76 |
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.77 | 0.71 | 0.84 |
| AdvancedEAST | 0.83 | 0.9 | 0.76 |
| Baseline (HQ) | 0.67 | 0.73 | 0.61 |
| Language (Script) | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Arabic | 0.83 | 0.9 | 0.76 |
| English (Latin) | 0.86 | 0.96 | 0.77 |
| French (Latin) | 0.84 | 0.98 | 0.74 |
| Russian | 0.75 | 0.96 | 0.62 |
| Italian (Latin) | 0.88 | 0.98 | 0.79 |
| Chinese | 0.93 | 0.99 | 0.88 |
| Korean | 0.84 | 0.96 | 0.75 |
| Portuguese (Latin) | 0.78 | 0.98 | 0.65 |
| German (Latin) | 0.83 | 0.98 | 0.72 |
| Japanese | 0.81 | 0.97 | 0.69 |
| Spanish (Latin) | 0.85 | 0.97 | 0.75 |
| Model | Weights size (MB) | Estimated size after quantization (MB) |
|---|---|---|
| Seglink on DenseNet | ~50 | ~14 |
| AdvancedEAST | ~60 | ~15 |
Система распознавания номерных знаков
Задача
Требовалось создать компонент для анализа транспортного потока и распознавания номерных знаков в разных условиях съемки. Алгоритм должен был находить область номера и извлекать символы из видеопотока.
- локализация номерного знака на изображении;
- распознавание последовательности символов;
- устойчивость к погодным условиям и перспективным искажениям;
- интеграция в библиотечный компонент.
Решение
Для обнаружения использовались модели YOLOv5 и YOLOv8, для распознавания — CRNN. Данные были переразмечены и использованы для дообучения детектора и OCR-модуля. Для повышения устойчивости применялись аугментации и методы проективной геометрии.


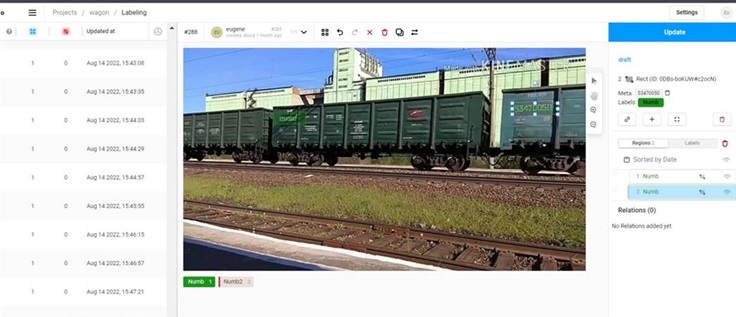
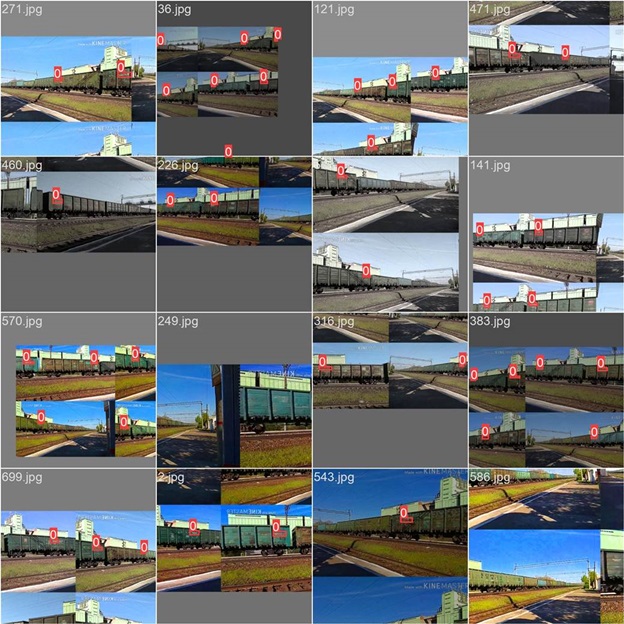
Распознавание номера вагона поезда
Подход
На первом этапе были собраны реальные изображения и видеозаписи проходящих поездов в разных условиях. Затем данные были размечены в Label Studio: для каждого номера вагона выделялась область на изображении.
Результат
Компоненты обнаружения YOLOv8 и распознавания CRNN были дообучены на собранном наборе данных. Общая точность распознавания на тестовой выборке составила 89%, что подтвердило переносимость подхода на смежные задачи транспортной видеоаналитики.
Система распознавания QR-кодов и штрихкодов
Задача
Нужно было оценить надежность распознавания QR-кодов и штрихкодов при изменении размера кода в кадре, угла поворота, обрезки и качества изображения. Отдельно анализировалась разница между простыми и сложными QR-кодами.
Выводы
- QR-коды считывались надежнее штрихкодов при сопоставимом размере в кадре.
- Сложные QR-коды требовали большей доли площади кадра для стабильного чтения.
- Для штрихкодов критичны размытие, угол поворота и обрезка области.
- При углах поворота порядка 40° и выше качество распознавания резко снижалось.



Распознавание текста произвольной формы
Задача
Требовалось распознавать текст произвольной формы, различные шрифты, маркировки и надписи при разных уровнях шума, материалах поверхности и условиях съемки.
Для сравнения использовались PaddleOCR, Tesseract, Doctr и EasyOCR. Отдельно был собран набор из 1210 фотографий объектов из металла, пластика, стекла, кирпича, бумаги и дерева.
Решение
Существенная часть ошибок была связана не с распознаванием символов, а с определением положения текста. Для решения был добавлен внешний детектор на небольшой модели YOLOv8, а также синтетический набор из 10 000 изображений промышленных помещений с латинскими и кириллическими шрифтами.



Сравнение библиотек OCR
| Material/Model | PaddleOCR | Tesseract | Doctr | Doctr |
|---|---|---|---|---|
| Metal | 0.057160 | 0.461613 | 0.268681 | 0.181886 |
| Brick | 0.353260 | 0.041227 | 0.335991 | 0.103651 |
| Glass | 0.307380 | 0.254498 | 0.270838 | 0.212571 |
| Plastic | 0.947816 | 0.210128 | 0.147302 | 0.017100 |
| Paper | 0.377727 | 0.223795 | 0.270136 | 0.135312 |
| Wood | 0.055672 | 0.189703 | 0.188016 | 0.014465 |
| Miscellaneous | 0.124016 | 0.045473 | 0.021668 | 0.031424 |
Компьютерное зрение для реальных производственных и транспортных задач
Эти проекты показывают один подход: сбор и подготовка данных, выбор архитектуры, дообучение модели, проверка метрик и интеграция результата в прикладной модуль для работы с изображениями или видеопотоком.